In my last post How to build asymmetric pivots on Power Pivot data models I showed you how to build asymmetric reports with Power Pivot, using Named Sets. The result of that post was a Named Set, which you had to choose from the PivotTable fields list manually. This post is about how not to select a new Named Sets from the PivotTable fields list, each time you want to change the period, but how to use slicers to take control over the choosen Named Sets.
The goal of this post is, to improve the selection of the Named Set, you want to see in your pivot table. For doing that you first have to understand what really stands behind Named Sets. Named Sets are defined in MDX (Multidimensional eXpressions), a language to query OLAP cubes. Even when you used the wizard to create your first Named Set, you created an MDX statement. I have absolutely no clue about MDX, but Chris Webb published a series of posts, named Introduction to MDX for PowerPivot Users and I can only recommend to read it for deeper understanding of the topic.
Now let’s see, how you can see the MDX behind your Named Sets.
Finding the MDX behind Named Sets
To see the MDX-Statements behind the Named Sets you created with the wizard, follow these steps:
- Click into the pivot table
- Select the context sensitive menu PivotTable Tool
- Click on Tab Analyze
- Choose Manage Sets
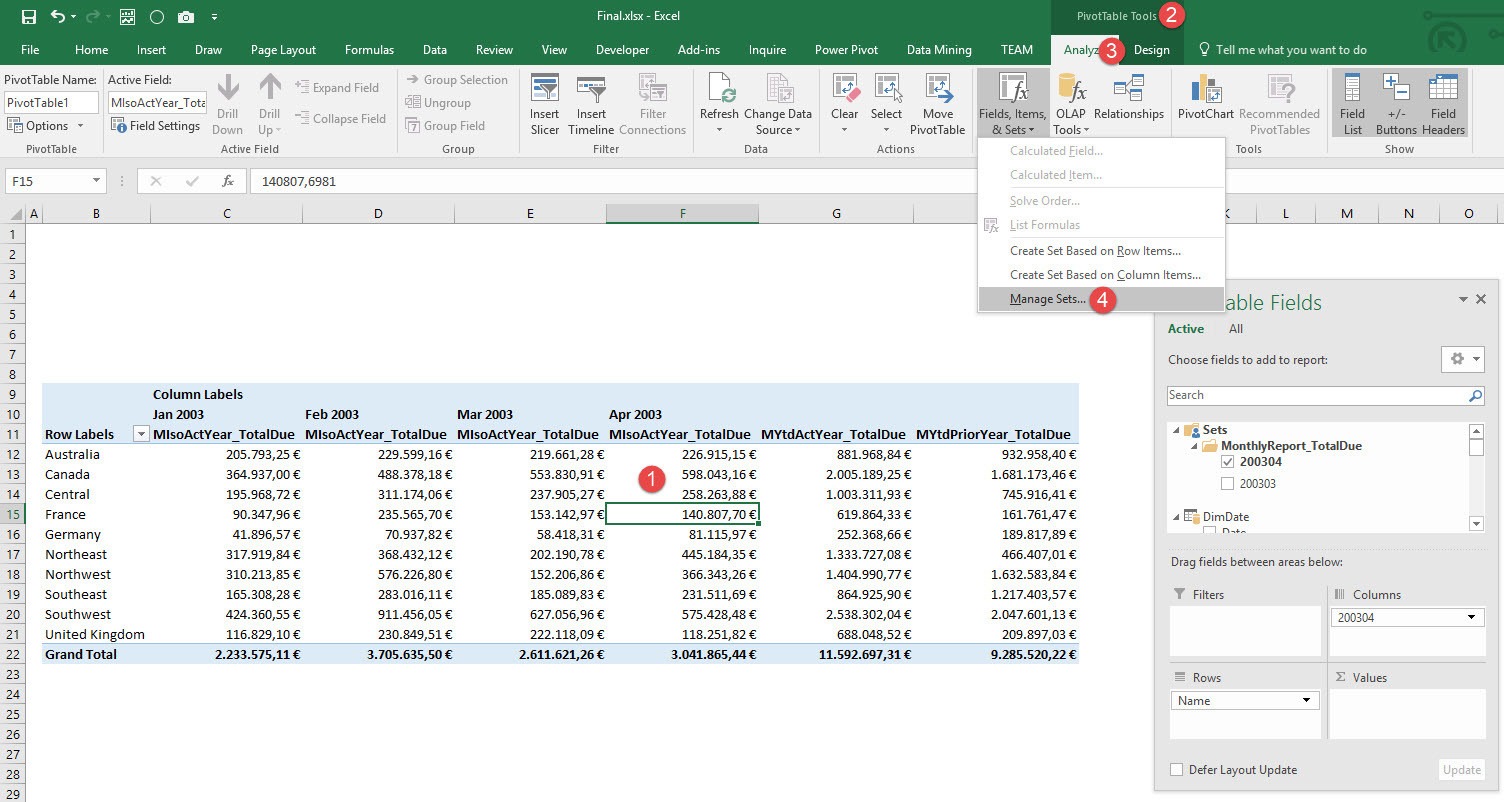
The next windows, that opens is the Set Manager. Select the Named Set you want (1) to see the MDX statement and then click in Edit (2).
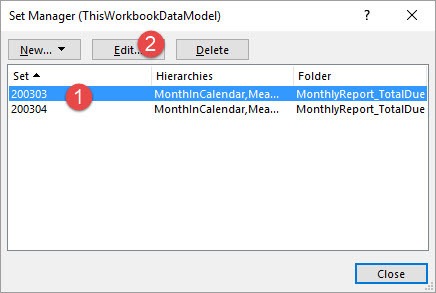
The following windows is already your good friend. Here you created all the Named Sets so far. But have you noticed the little button Edit MDX on the lower right? Click on it (1) and confirm the appearing warning with OK. Then press OK (2) in this window.
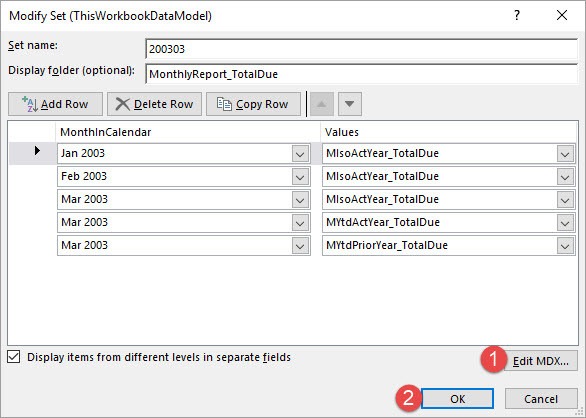
After confirming with OK you see the following MDX statement.
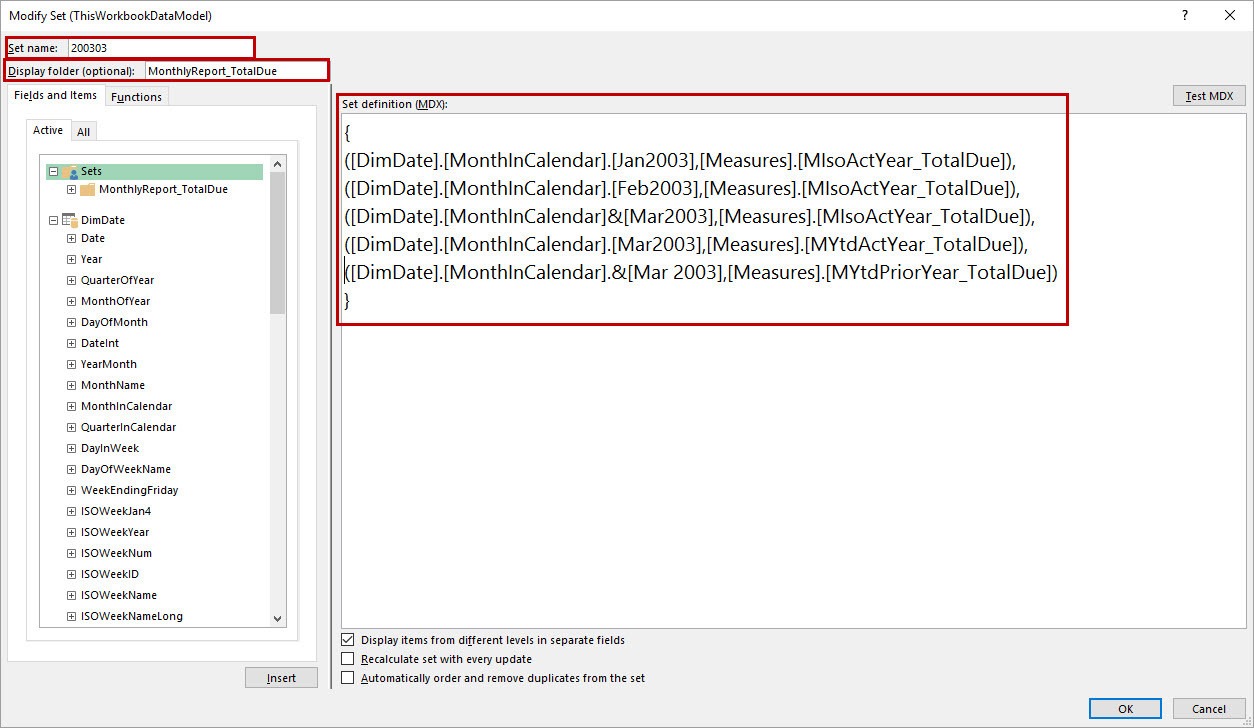
What does this statement mean. As I sayed before: For getting an perfectly technical background on MDX for PowerPivot read Chris‘ posts. I will keep it less technical . See the following figure.
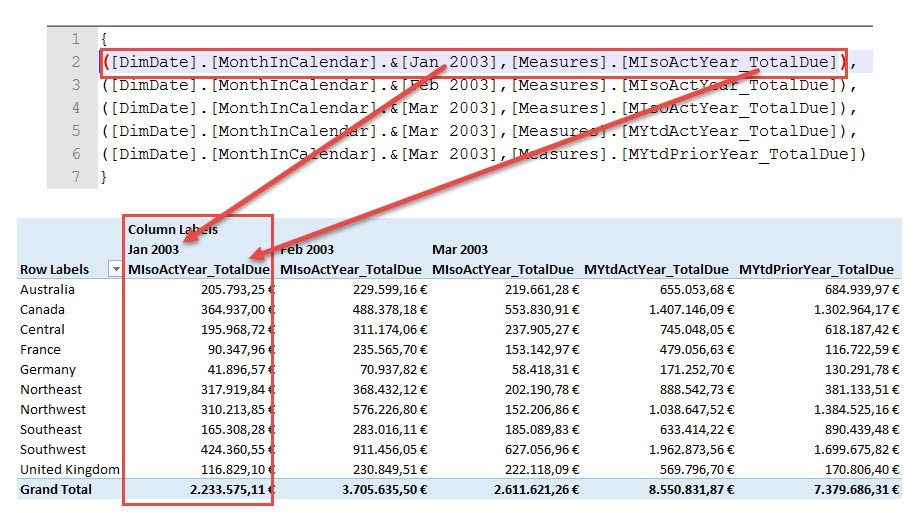
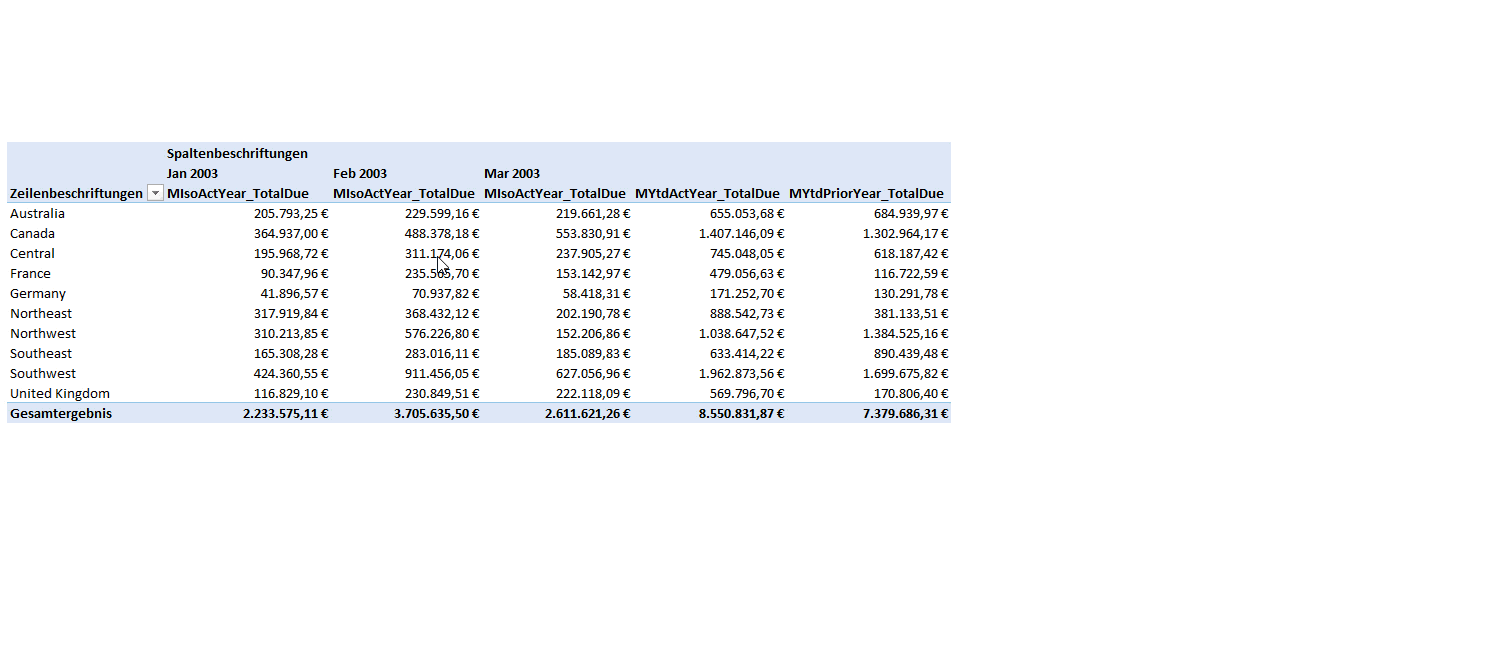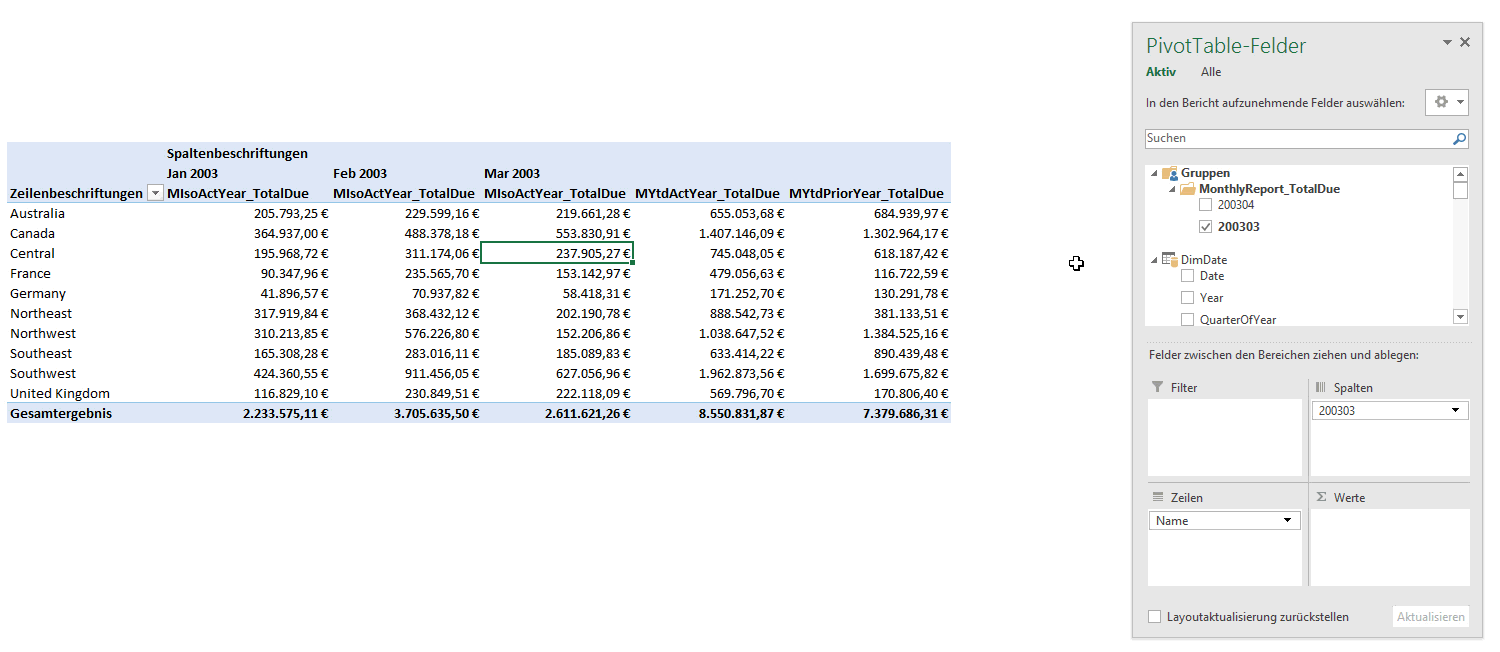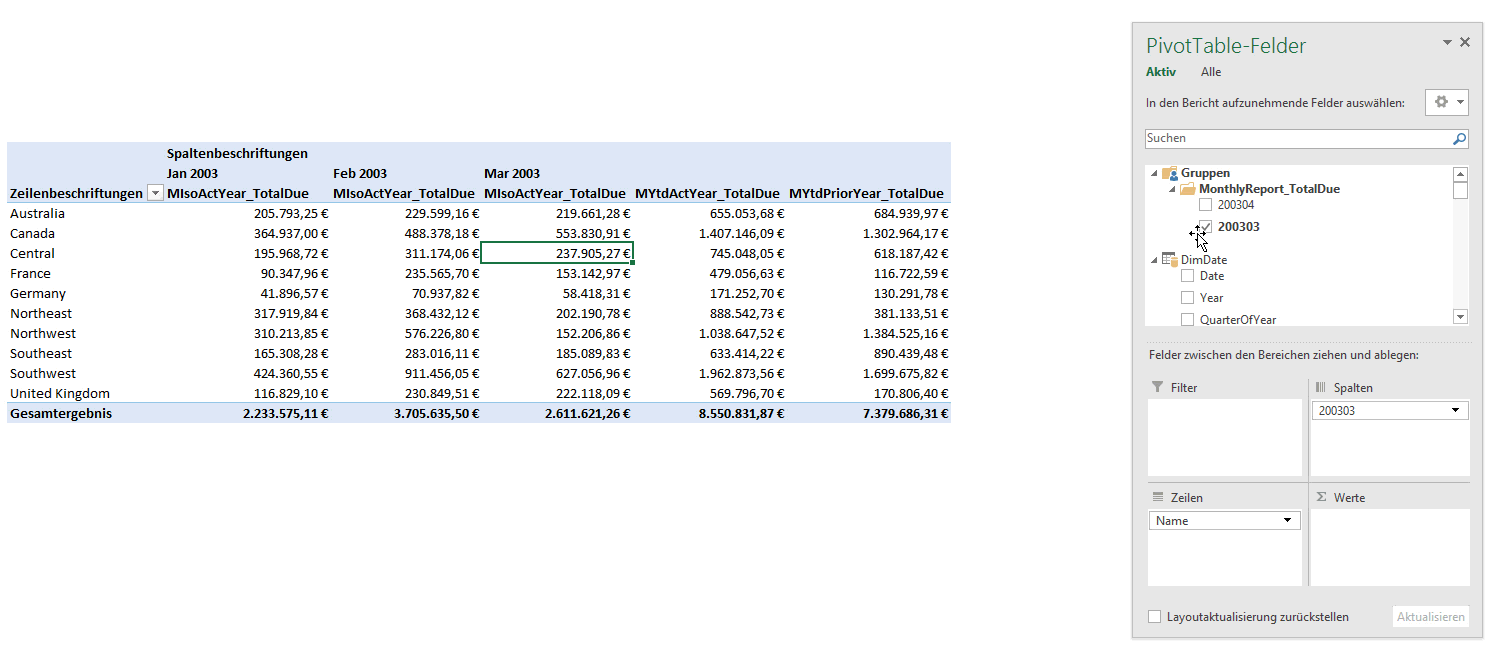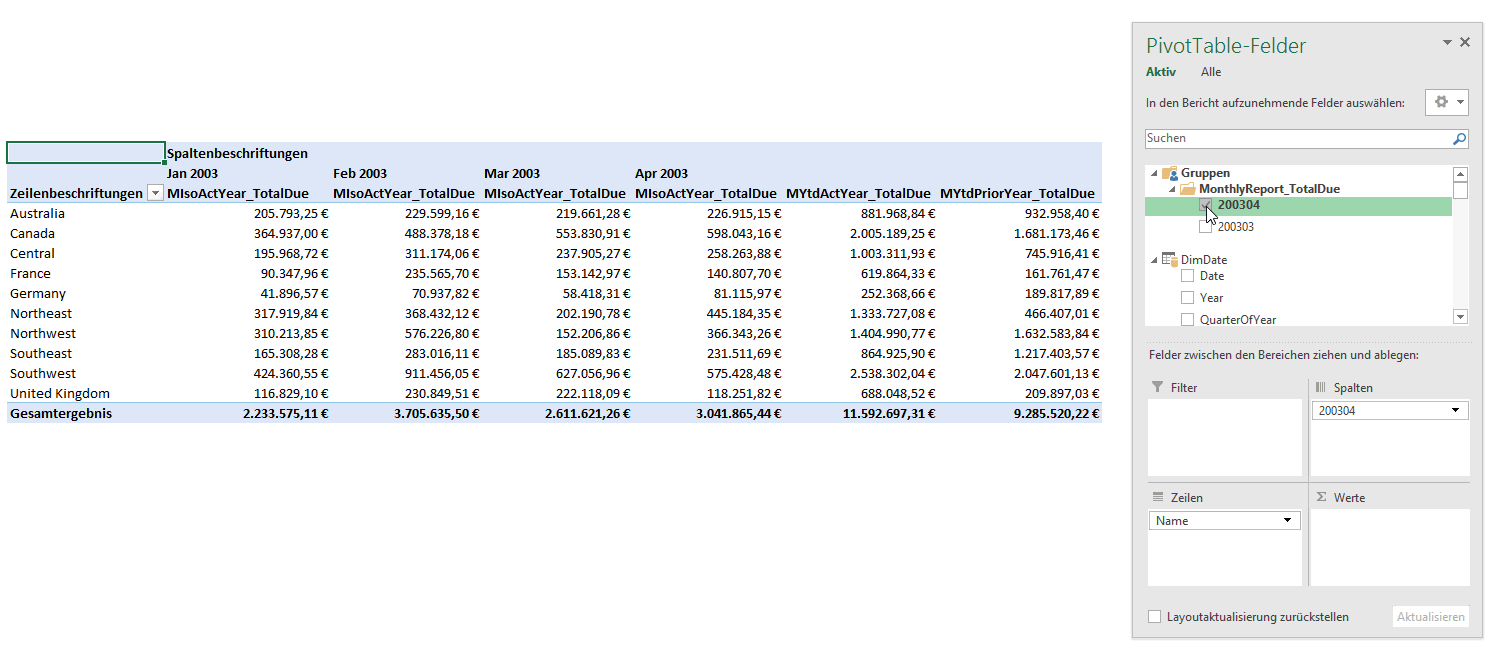
Because we created all the Named Sets on columns (not on rows) each line (except line 1 and 7) in the MDX statement represents a column in the pivot table. Let’s focus on line 2. This line consists of a selected month (in this case January 2003) and a measure (MIsoActYear_TotalDue = TotalDue of the isolated January in Year 2003).
Now, that we know how a Named Set looks in MDX, there is one more question to overcome: How can we make this Named Set react on a slicer?
How to make Named Sets react on slicers
The good news is, that the xVelocity engine, which stands behind Power Pivot, understands both: MDX and DAX 🙂 This is something I learned from Idan Cohen’s post about Dynamic Chart in Power Pivot on Powerpivotpro.com. And this is where the naming convention of your Named Sets comes back into the game. I want to do the following steps:
- Building a parameter table in the Power Pivot data model, that includes a column with all the names of the Named Sets (e.g. 200301, 200302, 200303, …, 200512)
- Creating a slicer based on that parameter table
- Creating a DAX measure, that retrieves the single selected value in the slicer (the selected name of the Named Set)
- Creating an MDX statement, that reacts on the written DAX measure
These four steps make it happen, that you can control your Named Sets by slicer. Let’s move on 🙂
Build a parameter table in the Power Pivot data model
For being able to control Named Sets via Slicer, we first need to create a parameter table. ‚Parameter table‘ is another word for disconnected table, which is a single table in the data model, that has no relation to other tables. Our table will have two columns:
a) Column ‚Caption‘: This column will be shown in the slicer and will let the user select the year-month-combination.
b) Column ‚YYYYMM‘: This column will show the year-month-combination as number. This will be read by the Named Set and will change the pivot structure accordingly.
Let’s take a look at how it works.
I open a new excel sheet within the same file. The data looks like this:
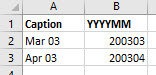
You need to ensure, that in this table are only those months represented, for which you already have created a Named Set. For example: We created two Named Sets. One for March 2003 and one for April 2003. Only those two months appear in this table now. This is important for the MDX-statement, which will let us control the Named Sets by Slicer. When you will create further Named Sets in the future, it will be pretty easy to enlarge the parameter table within seconds. I will show later, how that works.
Now we convert these two columns into a table the following way:
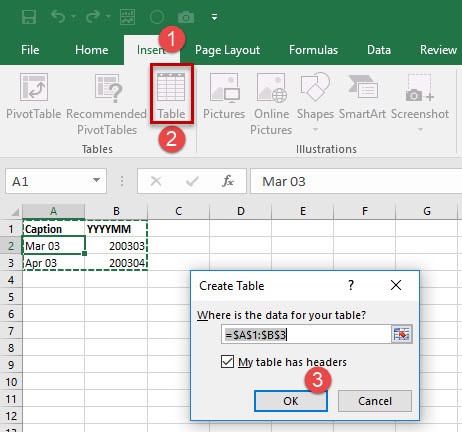
The advantage of going this way is, that you can change the table name, before you add that table to the data model. That way the name of your table in Excel and the name of the table in the data model are equal. This is not strictly required, but it’s pretty usefull. Change the name under ‚Table Name‘ (Step 2) in what ever you like. I use ‚ParameterTable‘ for this example.
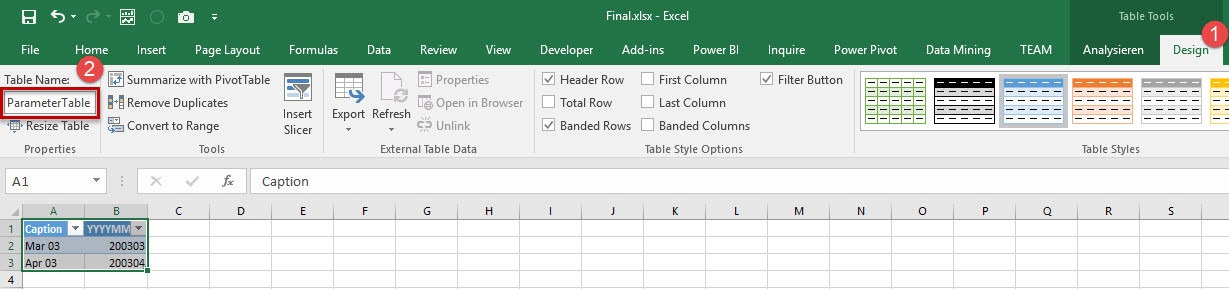
After we renamed the table name, we can now go and add that table to the data model.
The result in the data model looks like the following:
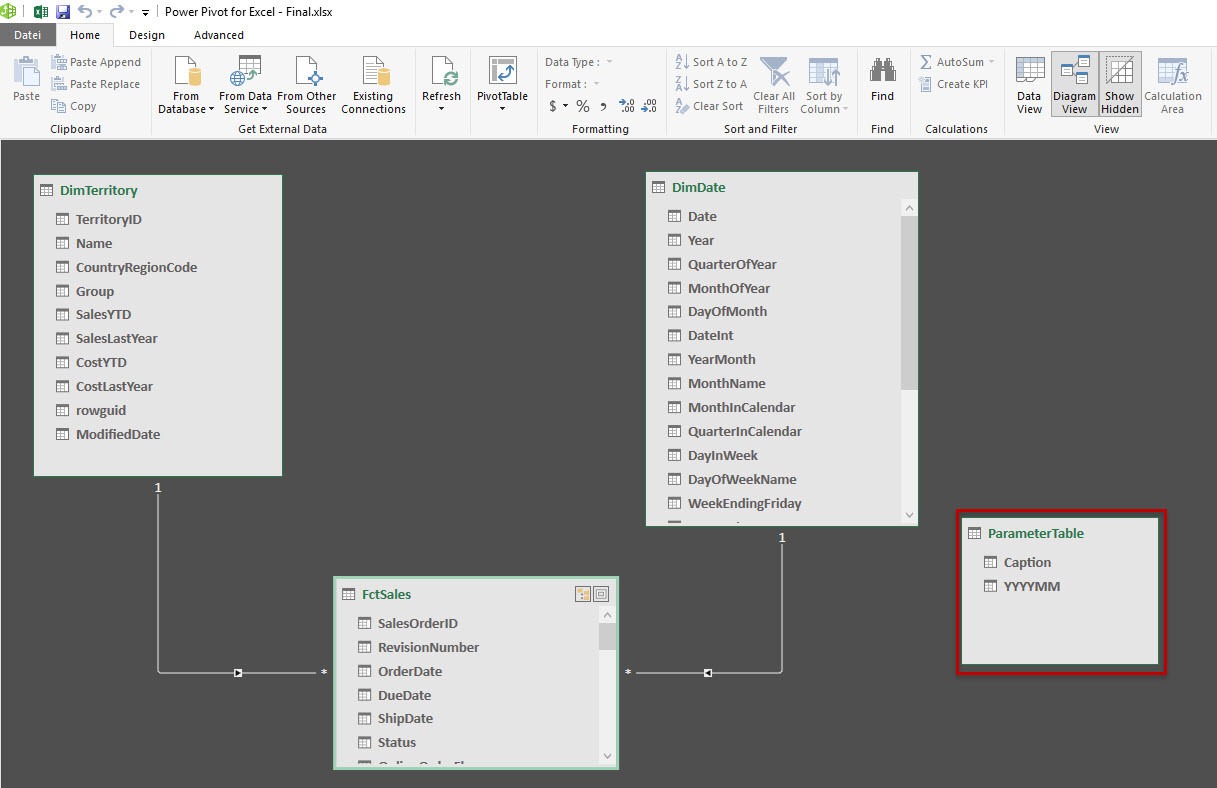
Data model with parameter tableNow that we’ve got the newly added table in our data model, we can now create a slicer using this table.
Creating a slicer based on the parameter table
Because we want to be able to control a Named Set (which allows us an asymmetric report in a pivot table) via Slicer, we created a (not connected) parameter table to the data model. It is important that you use a disconnected table, because we don’t want other tables in the data model to be filtered, when we select something from the slicer. We only want to be able to define the structure of the pivot table. Therefore the table used for the slicer musn’t have any relations to other tables.
Creating a slicer on that disconnected table works as follows:
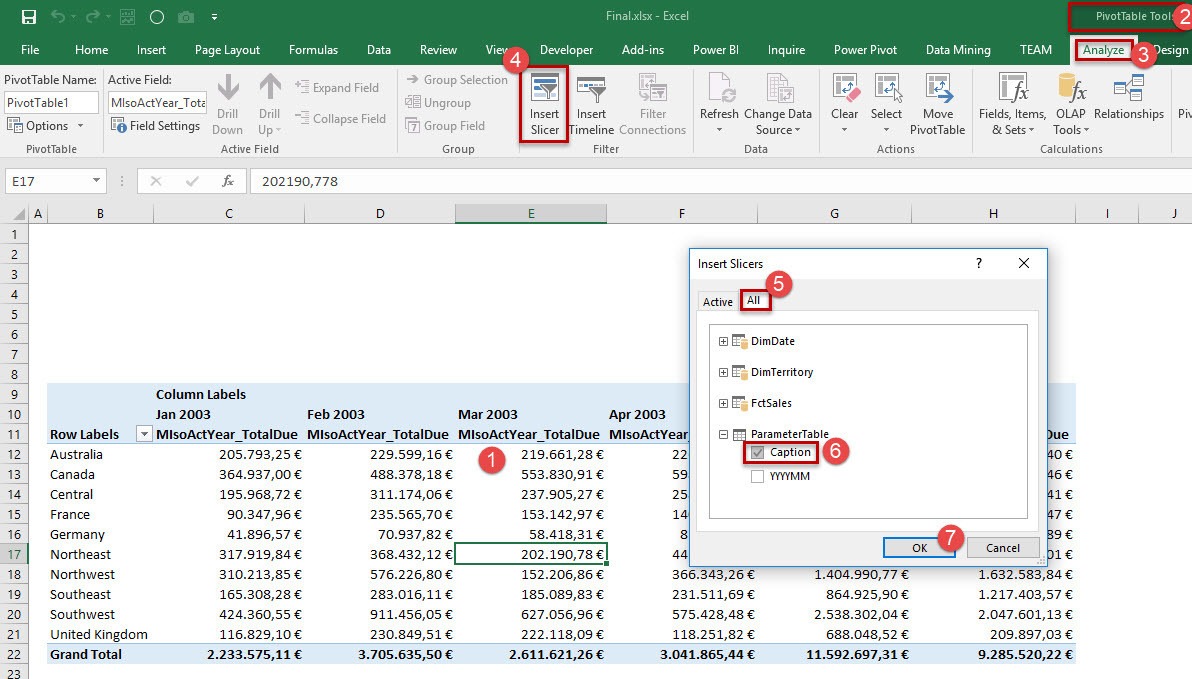
For adding a slicer to the pivot table click somewhere into the pivot table (1), click on the context sensitive menu PivotTable Tools (2) and on Analyze (3). Clicking on Insert Slicer (4) opens a window, which lets you see the Active and All tables of the data model. Choose tab All (5) and you will be able to select column Caption from the newly added parameter table. Confirm with OK (7). The result can be seen in the following figure:
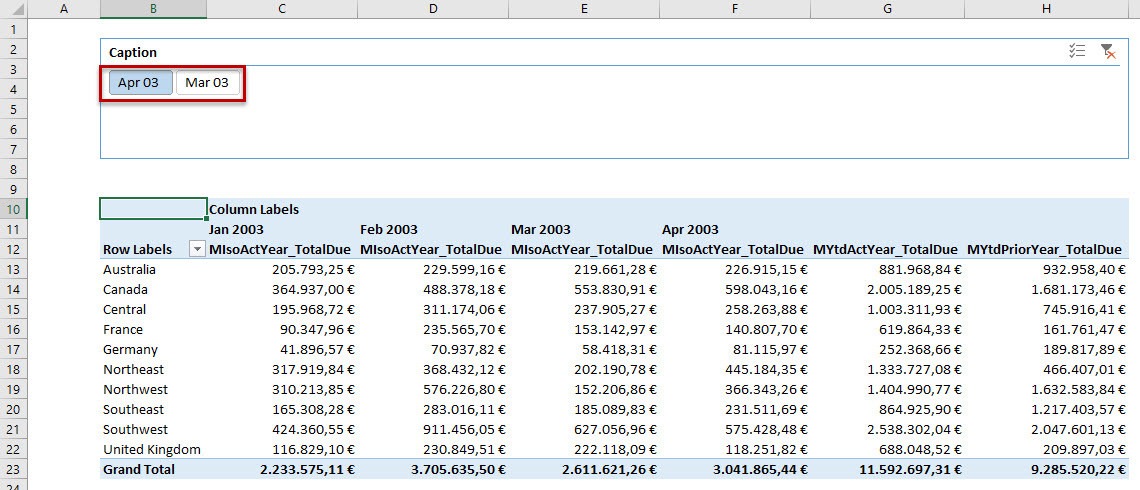
What you can see on the first sight is, that the months are sorted alphabetically, what is not usefull at all. Let’s go back to the data model and change this.
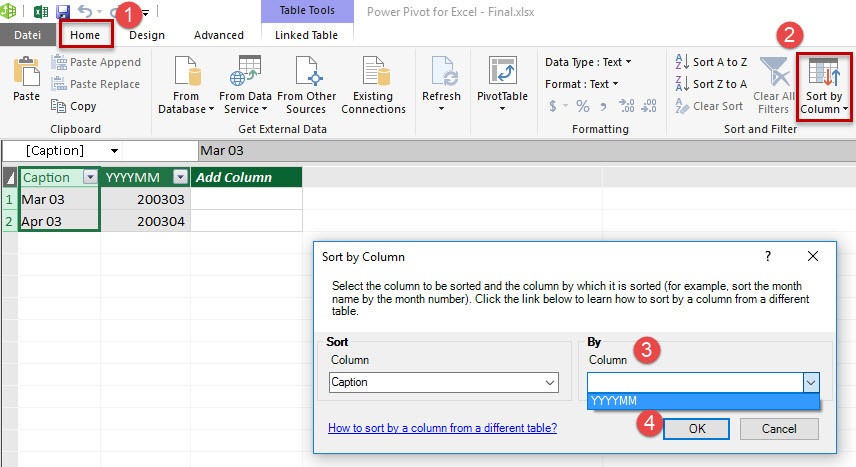
For changing the sort order of the month in the slicer, you have to change the sort order for the column ‚Caption‘ in the table of the data model. Click on the column you want to have sorted (‚Caption‘) and go to Tab ‚Home‘ (1) and click on ‚Sort by Column‘ (2). Then choose the column ‚YYYYMM‘ as column you want your column ‚Caption‘ get sorted by. Take care, that the column ‚YYYYMM‘ has a numeric data type. Otherwise you will get problems with sorting. Having that done, the slicers shows the correct sort order.
You will notice very quickly, that selection anything from the slicer will have no effect on the pivot table at all. The reason ist, that there is not relationship between the parameter table and any other table of the data model. So this behavior is exactely what we wanted. But what do we do with a slicer, that does not have any effect on the pivot table we want to change the structure? Stay patient, we are coming closer.
Creating the DAX measure, that reads slicer selection
Okay, the pivot table doesn’t get the information, which items where selected from the slicer. But we can evaluate the selection from the slicer using DAX. We can write a measure, that looks at the selection, evaluates if only one single item is selected (only one month at the time) and then give the selected item back. The following DAX statement does exactely what we want:
=
MIN ( ParameterTable[YYYYMM] )
![]()
If there is only one item selected from the slicer, the MIN() function will return the selected item of column [YYYYMM], because if it’s the only one, it’s the minimum at the same tim. If there are more items selected, the MIN() function will return the minimum of those.
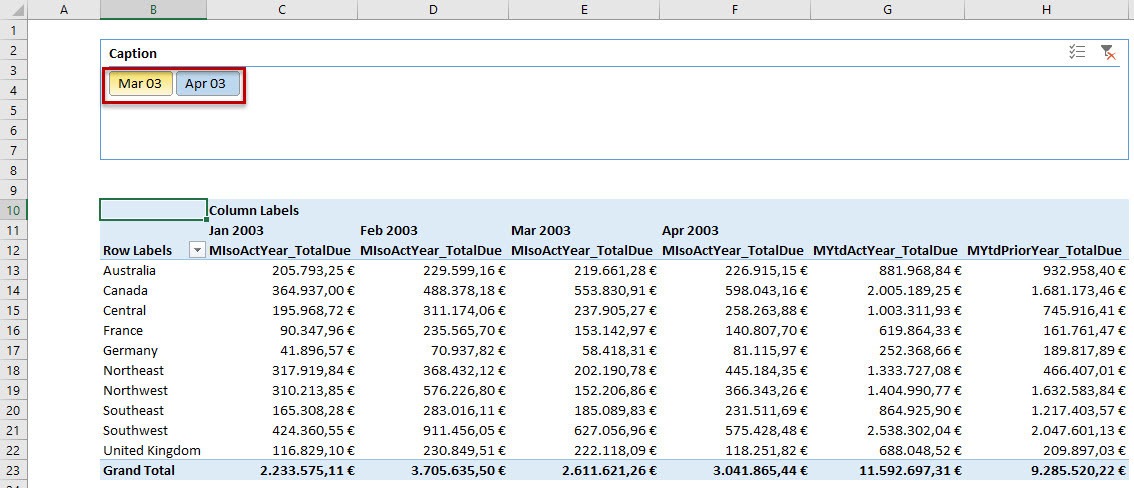
A good way to see, what this measure returns in relation to the slicer selection, is a very short cube-function in Excel:
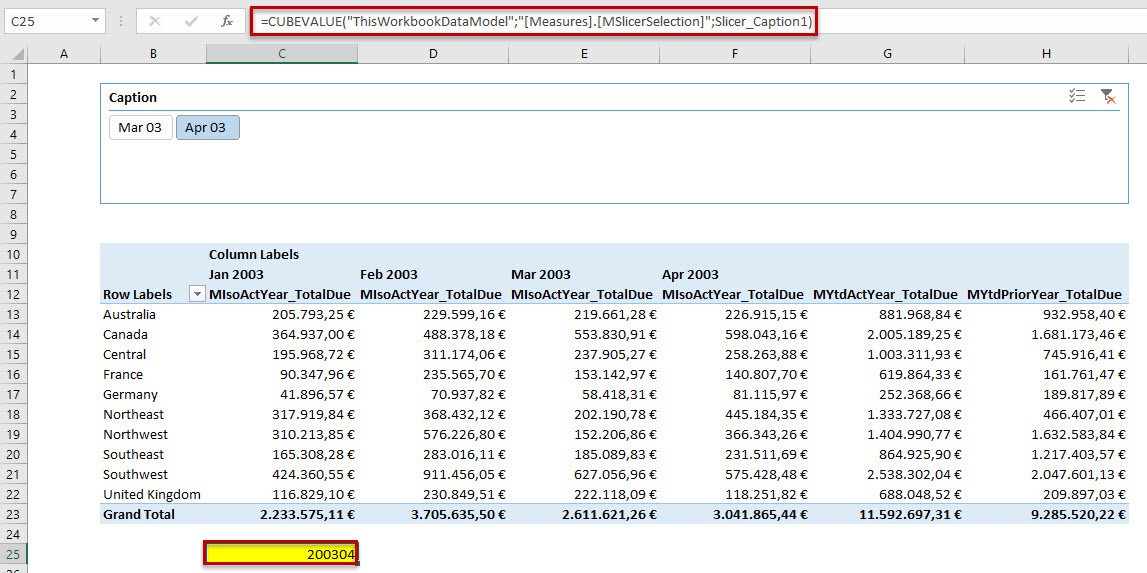
The CUBEVALUE function has three parameters.
- Connection: The formula connects to the power pivot data model and its tables, relations and measures.
- Measure: We define, that we want to get the values of the measure MSlicerSelection.
- Slicers: This is the name of of our slicer Caption, which filters the result of the CUBEVALUE function.
Now we know which items was selected, by using a DAX-Measure. The next step is, to pass this information to a MDX statement, that defines the structure of our pivot table. That way we don’t have to choose the wanted Named Set from the pivot table fields list, but can choose it via slicer, without even knowing, that there is a Named Set behind all that magic 🙂 Let’s go.
Modifying the MDX statement, to read the DAX measure
Before we connect the Named Sets to our Slicer we have to remove the selected Named set from the pivot table.
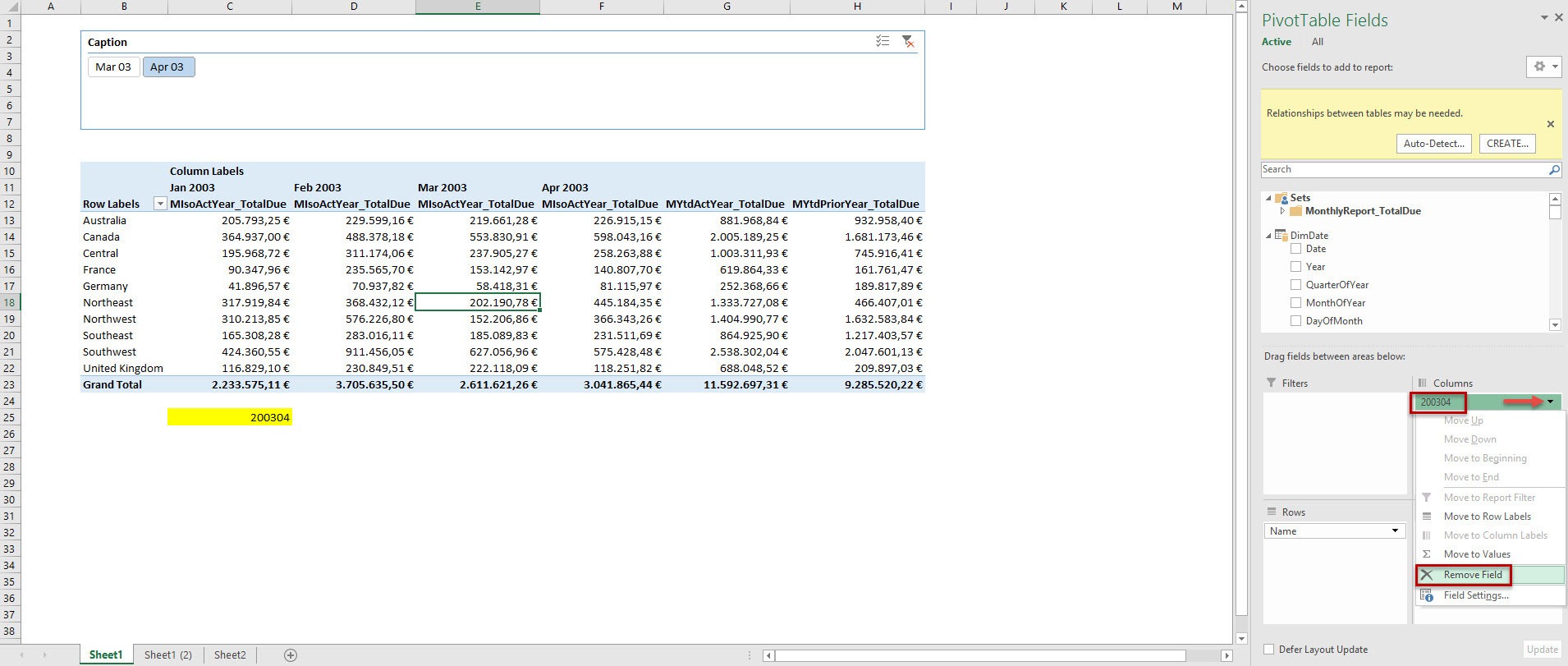
Now we can move on to create a new Named Set using MDX. First go to „Manage Sets“.
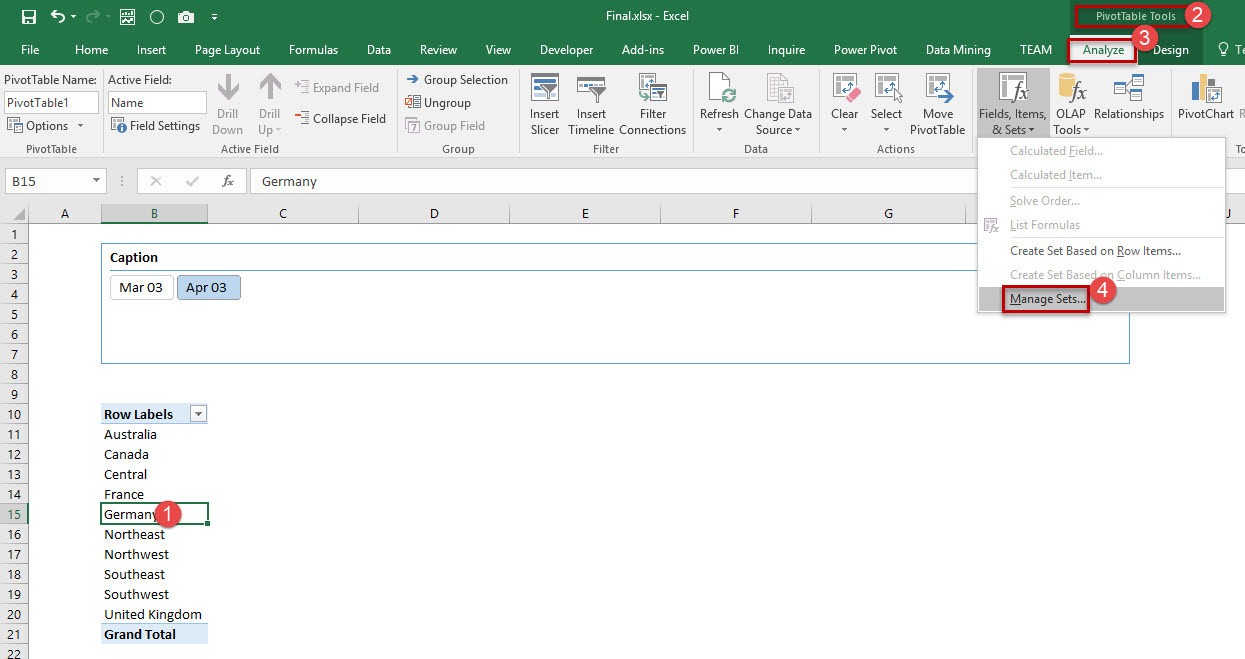
Then choose „New…“ (1) and „Create Set using MDX“ (2).
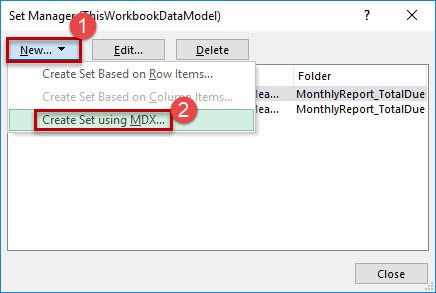
First give that Named Set a appropriate name (1). For keeping the overview over your Named Sets it’s good to put it in the folder of the other Named Sets. Unfortunately there is no dropdown to choose the folder name from. While writing take care to type it correctly (2). In the next step (3) you define the MDX statement the following way:
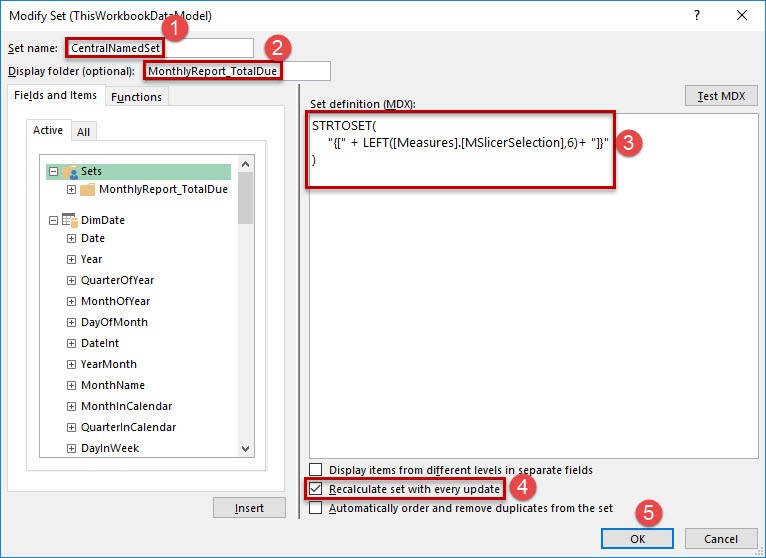
The StringToSet function (STRTOSET) converts a string into a set. I don’t have a clue about MDX. So there will be several ways to do that better. But using the LEFT function around my DAX measure, which reads the slicer selection, creates a string out of a number. This string is used by the STRTOSET function. So, if you select 200303 on the slicer, this selection will be converted into a string by the LEFT function. This string „200303“ will be converted into a set by the STRTOSET function. That way you connect your slicer with your created sets on a dynamic way.
And what happens next month, when a new month has to be added? There are 3 steps to be done:
- Create a new Named Set, e.g. 200305
- Add a new row to the parameter table (in Excel): Caption May 03, YYYYMM 200305
- Resize the parameter table in Excel and refresh the data model
After that you are able to select the new month from the slicer and see another set in your pivot table.
BE CAREFULL: Always do it this way! First create the Named Set, then add a new line to the parameter table. Excel crushes, if you add the line to the parametert able first, because the STRTOSET function will be looking for a Named Set, which doesn’t exists yet. Always create the Named Set first and add the line to the parameter table afterwards!!!
Wooo, that was a long journey. Thanks for staying with me for so long. Now you have created a connection between a slicer on a Power Pivot column and one MDX statement, that dynamically returns a specific Named Set. Look at the result:
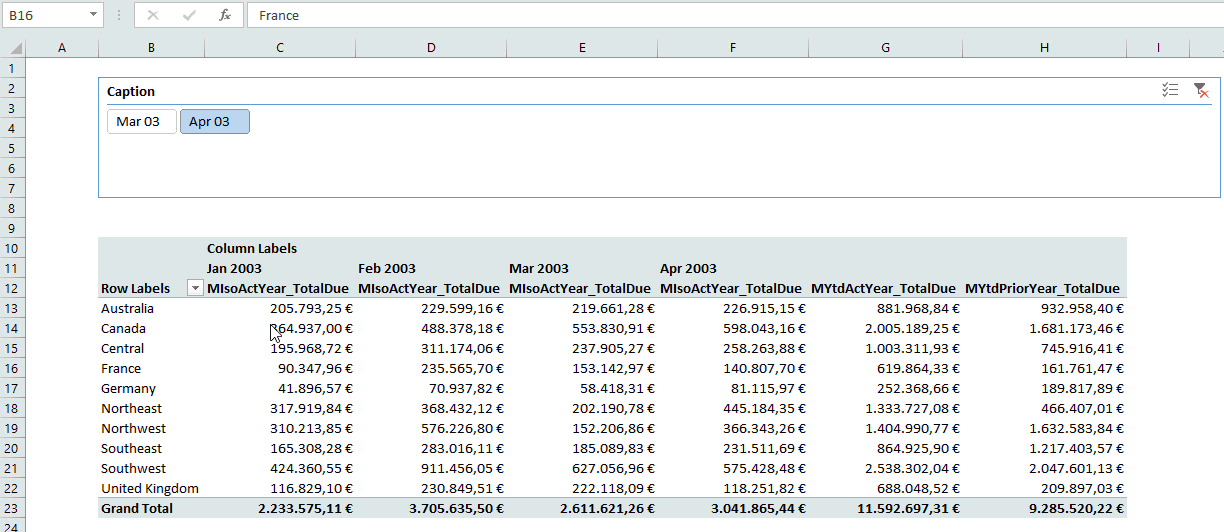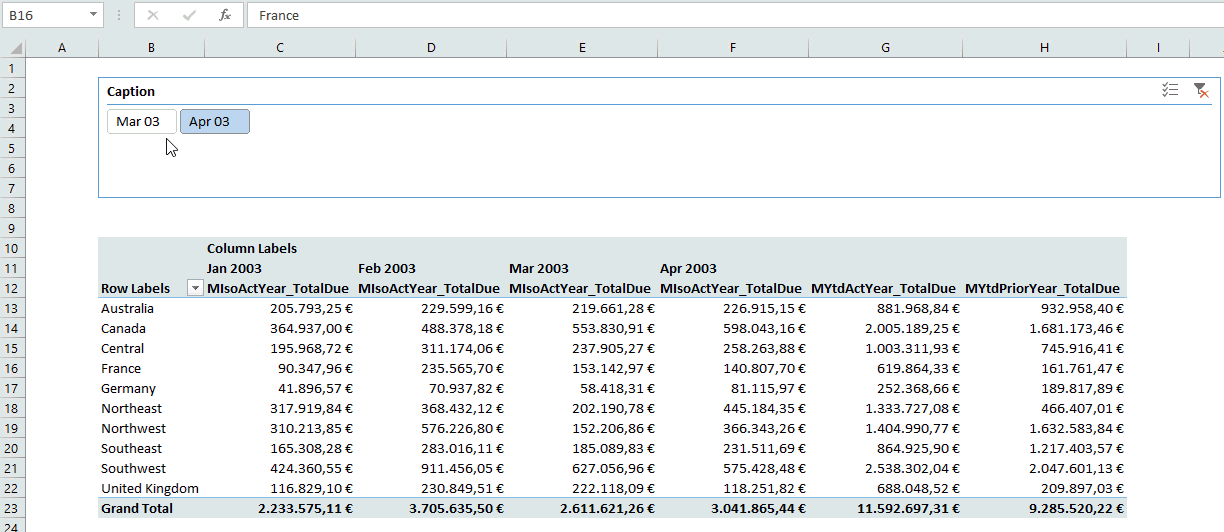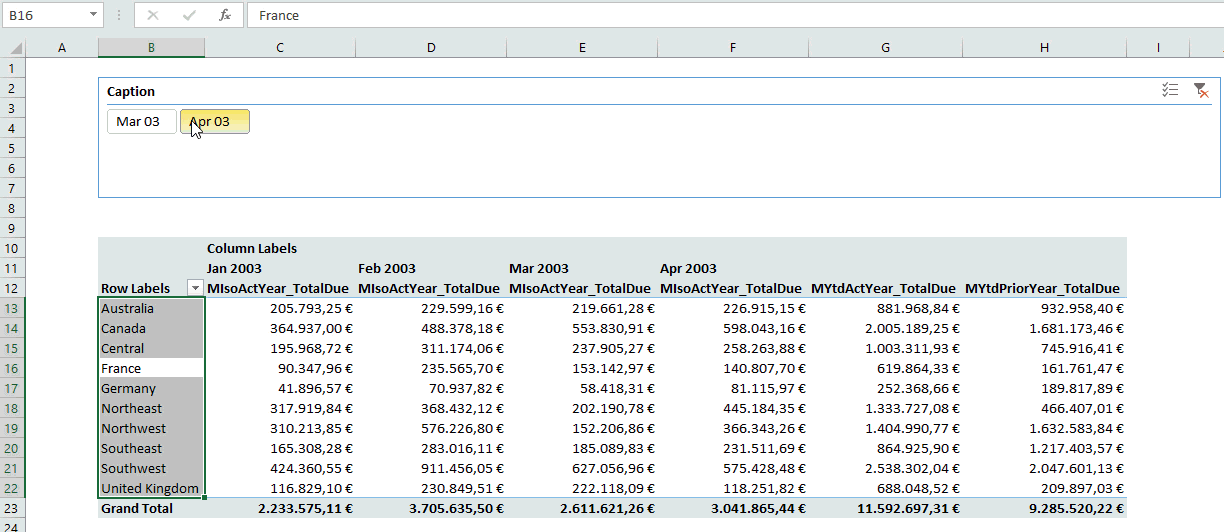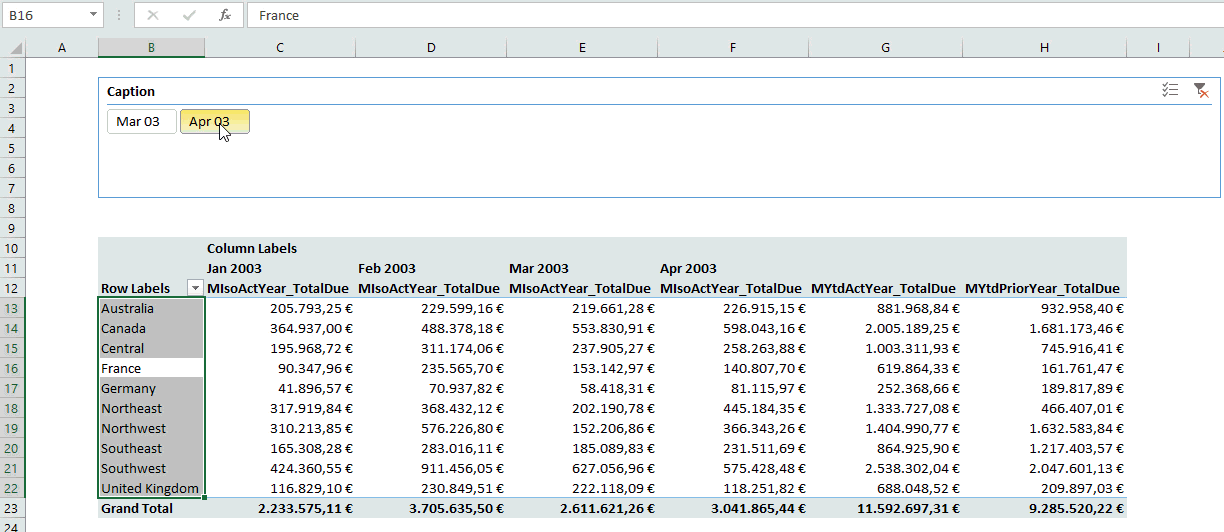
See you next time and keep in mind: Sharing is caring. If you liked this articel, feel free to share it
Greets from Hamburg,
Lars
Sie müssen den Inhalt von reCAPTCHA laden, um das Formular abzuschicken. Bitte beachten Sie, dass dabei Daten mit Drittanbietern ausgetauscht werden.
Mehr Informationen
Lars ist Berater, Entwickler und Trainer für Microsoft Power BI. Er ist zertifizierter Power BI-Experte und Microsoft Trainer. Für sein Engagement in der internationalen Community wurde Lars seit 2017 jährlich durch Microsoft der MVP-Award verliehen. Lies hier mehr…
Amanda meint
Hello! Thank you for your post! I’ve been trying to modify the MDX statement to read the DAX measure and have used your formula STRTOSET. However, everytime I press combined set in the pivot field list, it gives me an error about multiple changing dimensionality and my excel crashes. I’m currently using Excel 2016. I have tried the IIF fomula as well but my excel is still crashing due to the same error. Would appreciate any form of assistance from you. 🙂
Lars Schreiber meint
Hi Amanda,
I send to an email 🙂
Cheers,
Lars
Mike Mclachlan meint
Hi Lars,
I am trying to implement this technique and like Amanda I get an error when selecting another option on the slicer; „cannot handle a set that changes dimensionality“.
I have 2 sets currently and both sets work when adding them as sets, I just cannot get the slicer part to work! Any help most appreciated.
Cheers, Mike