In der Regel sind es die Faktentabellen, also die Ereignisse, die sich in einem Datenmodell regelmäßig ändern. Doch was ist, wenn den Dimensionen, also den Stammdaten, ebenfalls Änderungen widerfahren. Wie soll ich so eine Änderung in meinem Datenmodell abbilden, um mir das Leben einfacher zu machen? Dieser Frage geht der heutige Beitrag nach und zeigt Dir, wie Du die Herausforderung sich ändernder Dimensionen in Power BI angehen kannst.
Als Abonnent meines Newsletters erhältst Du die Beispieldateien zu den Beiträgen dazu. Hier geht’s zum Abonnement des Newsletters!
Die Problematik verstehen
Dass Du in Power BI (und vielen anderen BI-Tools) in mindestens 90% aller Fälle nach dem sog. Stern-Schema (engl. Star Schema) modellieren sollst, hast Du vermutlich schon einmal gehört. Falls nicht, kannst Du hier in der offiziellen Microsoft-Dokumentation eine tolle Zusammenfassung dessen lesen, was sich dahinter verbirgt. Dabei unterteile ich meine Tabellen im Datenmodell in sog. Fakten und Dimensionen. Die Fakten beinhalten Ereignisse (an der Kasse wird beispielsweise Umsatz erzeugt) und Dimensionen (Produktinformationen, Standortdaten des Point of Sales, etc.), die den Fakten Kontext verleihen. Eine Charakteristik dieser beiden Tabellentypen ist, dass Fakten sich quasi sekündlich ändern können (Umsatz wird hoffentlich häufig generiert), während sich die Dimensionen nicht ändern… Oder halt: Sagen wir lieber, sie ändern sich selten. Der vorliegende Beitrag soll Dir ein Beispiel dafür zeigen, wie Du Dein Datenmodell an sich ändernde Dimensionen anpassen kannst.
Sich ändernde Dimensionen (SCD2)
In der Welt der Business Intelligence gibt es mehrere Arten mit sich ändernden Dimensionen umzugehen. Die meiner Meinung nach gängigste ist die sog. Slowly Changing Dimension Type 2, oder kurz SCD2. Hier kurz ein Beispiel aus meiner eigenen Berufspraxis. Im Lebensmitteleinzelhandel ist es üblich, Supermärkte nach einer Zeit zu modernisieren. Nicht selten wird der Markt dabei auch umgebaut und seine Verkaufsfläche vergrößert. Da Umsatz je Quadratmeter eine wichtige Effizienzkennzahl im Controlling ist, ist es wichtig, jedem erzielten Umsatz, die richtige Quadratmeterzahl zuzuordnen, weil der Quotient sonst auf einer falschen Basis berechnet wird. Sieh Dir die folgenden beiden Quelltabellen an:
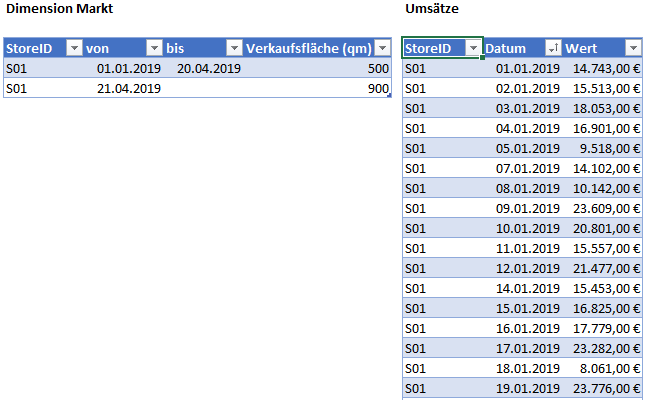
Die linke Tabelle „Dimension Markt“ beinhaltet aus Vereinfachungsgründen die Information für einen einzigen Markt. Jedoch beinhaltet diese Tabelle zwei Datensätze und nicht nur einen. Wieso das? Der Markt existiert seit dem 01.01.2019 und hat bis zum 20.04.2019 eine Verkaufsfläche von 500 Quadratmetern. Alle Umsätze (ersichtlich in der rechten Tabelle), die in diesem Zeitraum erzielt wurden, müssen also durch 500 geteilt werden, um den Umsatz je Quadratmeter korrekt berechnen zu können. Dem zweiten Datensatz in der Dimensionstabelle kann ich entnehmen, dass der Markt ab dem 21.04.2019 über eine größere Verkaufsfläche von 900 Quadratmetern verfügt. Alle Umsätze, die ab dem 21.04.2019 erzielt wurden, müssen also durch 900 geteilt werden, um Umsatz je Quadratmeter korrekt zu kalkulieren. Eine Sache nur kurz vorweg: Es gibt nicht den einen Weg, mit SCD umzugehen. Mich hindert beispielsweise technisch nichts daran, der Faktentabelle einfach eine weitere Spalte Quadratmeter hinzuzufügen, die zum jeweiligen Tagesumsatz des jeweiligen Marktes auch gleich die Quadratmeter des Marktes beinhaltet. Da es sich bei der Quadratmeterangabe jedoch um eine Information hinsichtlich des Marktes handelt, und weil ich die Quadratmeterzahl nicht (potentiell) millionenfach in der Faktentabelle wiederholen möchte, zeige ich Dir, wie Du es über die Dimensionstabelle lösen kannst.
Ein SurrogateKey als eindeutiger Identifikator
Wie im obigen Screenshot zu sehen ist, kann ich die Beziehung zwischen beiden Tabellen nicht auf Basis der StoreID vornehmen, da mir dies keine zweifelsfrei korrekte Verkaufsfläche zurückliefern würde. Nicht die StoreID ist eindeutig, sondern nur die StoreID in Kombination mit dem von- /bis-Datum. Daher muss ich im ETL-Prozes mit Power Query eine neue – künstliche ID erzeugen: Den sog. SurrogateKey, zu deutsch Ersatz-Schlüssel.
Den SurrogateKey in der Dimensionstabelle erzeugen
Da ein SurrogateKey ein eineindeutiger Schlüssel innerhalb der Dimensionstabelle sein soll, kann ich hier einfach mit einer neuen berechneten Spalte arbeiten, die mir einen Index einfügt. Somit bekommt jede Zeile in der Dimensionstabelle eine neue, fortlaufende – und damit eineindeutige – Nummer.

Damit ich auf Basis des SurrogateKeys mit der Faktentabelle eine Beziehung erstellen kann, muss dieser natürlich zunächst in die Faktentabelle integriert werden.
Den SurrogateKey in der Faktentabelle erzeugen
Den SurrogateKey der Märkte nun auch in die Faktentabelle zu bekommen, ist ein wenig komplexer. Zunächst führe ich die beiden Tabellen auf Basis der StoreID zusammen. Ausgehend von der Faktentabelle, führe ich einen LEFT OUTER Join durch und nutze die StoreID als Schlüssel zwischen beiden Tabellen. Falls Du über die Unterschiede zwischen den einzelnen Join-Arten lernen möchtest, empfehle ich Dir diesen Beitrag.
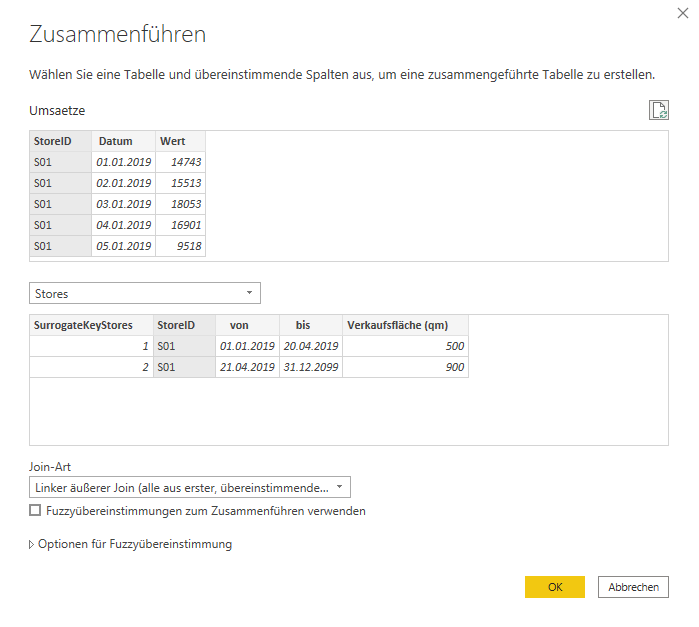
Da die StoreID nicht als eindeutiger Identifikator fungiert, liefert der Join (siehe Screenshot) alle Datensätze zurück: in diesem Fall also 2 Datensätze.
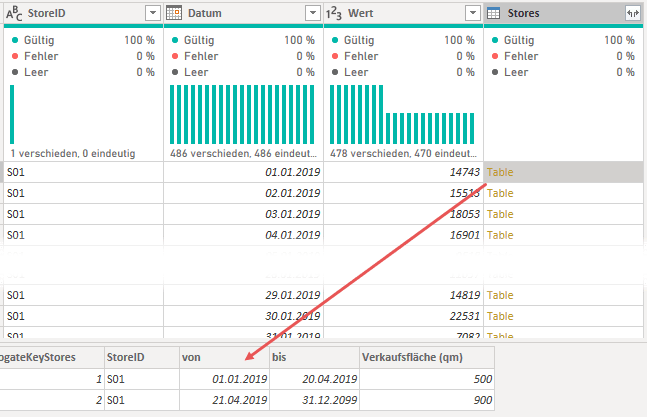
Der nächste Schritt ist also, den Datensatz zu extrahieren, der für das entsprechende Umsatzdatum relevant ist. Dies erfolgt über eine neue berechnete Spalte und folgende M-Formel:
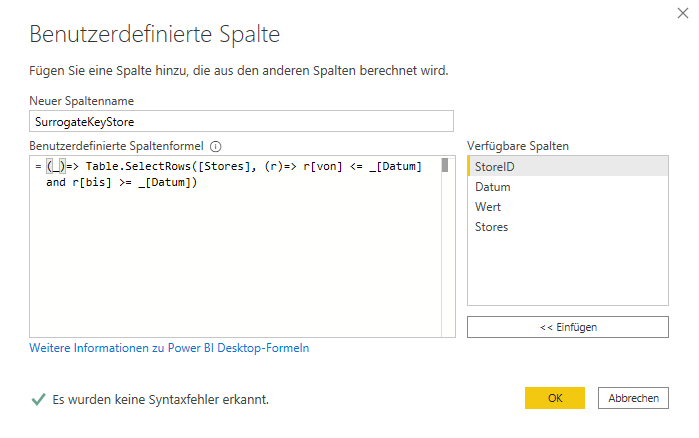
Ich gehe an dieser Stelle nicht auf den technischen Hintergrund dieser Formel ein. Falls Dich dieser jedoch interessiert, kannst Du in der Serie zu den Environments in M, speziell im 4. Teil, alles Wissenswerte dazu lesen. Im Ergebnis habe ich den SurrogateKey für die Märkte nun sowohl in meiner Dimensionstabelle als auch in meiner Faktentabelle. Dieser liefert mir die korrekte Quadratmeterzahl für Markt und Umsatzzeitpunkt:
Wie kann ich dies nun in meinem Berechnungen nutzen?
Verwendungsmöglichkeiten
Durch die nun vorliegende Modellierung ist es mir möglich, den Umsatz je Quadratmeter mit einem einfachen Measure zu kalkulieren:
Umsatz je qm =
SUMX ( Umsaetze, DIVIDE ( [Wert], RELATED ( Stores[Verkaufsfläche (qm)] ) ) )
Dieses Measure kann dann beispielsweise wie folgt Verwendung finden:
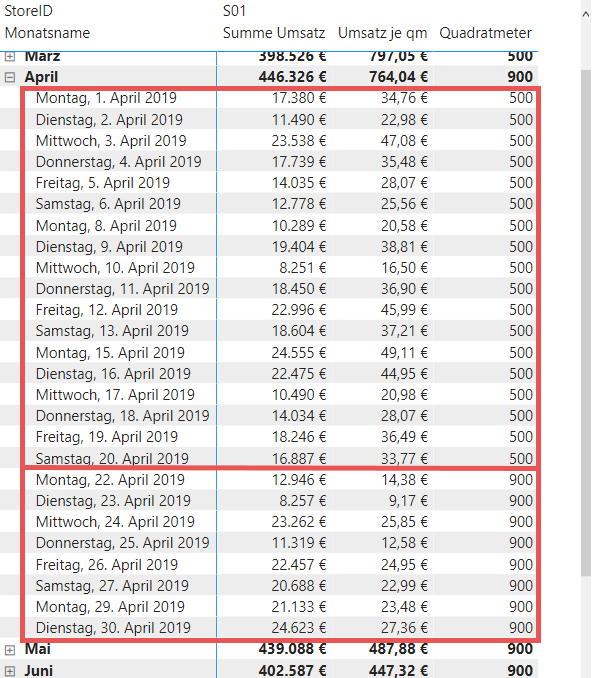
Bis zum nächsten Mal und denk dran: Sharing is caring. Wenn Dir der Beitrag gefallen hat, dann teile ihn gerne. Falls Du Anmerkungen hast, schreibe gerne einen Kommentar, oder schicke mir eine Mail an lars@ssbi-blog.de
Viele Grüße aus Hamburg,
Lars

Lars ist Berater, Entwickler und Trainer für Microsoft Power BI. Er ist zertifizierter Power BI-Experte und Microsoft Trainer. Für sein Engagement in der internationalen Community wurde Lars seit 2017 jährlich durch Microsoft der MVP-Award verliehen. Lies hier mehr…

Jannis meint
Hallo Lars,
ein cooler Beitrag. Dies funktioniert in ersten Tests auch super, sofern die Datenmenge überschaubar ist. Da wir aber mit Datensätzen arbeiten, die nun doch etwas größer sind (Dimension ~300k Zeilen; Fakt ~20 Millionen Zeilen), führt dies zu endlosen Ladezeiten, die sich bei aktuellem Tempo in die Wochen ziehen :/
Hast du diesbezüglich ein Trick, wie diese Technik auch bei großen Datensätzen anwendbar ist ?
Vielen Dank vorab und Grüße
Jannis
Lars Schreiber meint
Hi Jannis,
bei solchen Datenmengen ist meine gezeigte Lösung in der Tat super langsam. Das lässt sich mit Power Query auch nicht wirklich stark beschleunigen. In solchen Fällen sollte man die die SCD2-konformen Dimensionen außerhalb von Power BI aufbereiten lassen, z. B. mit Talend Open Studio.
Liebe Grüße,
Lars
Marcus Wegener meint
Hi Jannis,
hast du mal versucht die Surrogate-Key Zuordnung über eine DAX-Berechnete-Spalte zu erstellen? Aus meiner Sicht müsste das schneller gehen, da die Daten dann erstmal ohne Lookup ins Power BI Datenmodell geladen werden.
Ich habe da auf Basis von Lars Beitrag, einen um DAX ergänzenden Beitrag erstellt.
https://www.biordie.com/post/tutorial-stammdaten-zuordnung-mit-datumsbezug
Viele Grüße
Marcus
Sascha Weber meint
Cooler Beitrag. Very Nice
Michael meint
Ich habe die Funktion bei mir korrekt implementiert für die Calculated Column. Allerdings steht in jeder Zeile kein SurrogatKey sondern immer nur der Wert Function in gelb, also als Referenz. Braucht es hier noch weitere Schritte, die nicht abgebildet sind?
Lars Schreiber meint
Hallo Michael,
nein, die gezeigten Schritte sind genau die, die Du für das Ergebnis brauchst. Ich vermute Du hast bei der Formel der berechneten Spalte den Unterstrich übersehen und „()=>“ statt „(_)=>“ geschrieben. Wenn Du den Unterstrich weglässt, dann wird Dir das Funktionsobjekt zurückgegeben und nicht der SurrogateKey. Löst das Dein Problem?
VG,
Lars
Marcus meint
Hi,
über den Dialog „Benutzerdefinierte Spalte“ wird dem M-Code ein „each“ vorangestellt.
Wenn dieses über die „Bearbeitungsleiste“ entfernt wird, wird aus dem Wert „Function“ eine „Table“.
Beste Grüße
Marcus
Marcus meint
Zack und schon ist man wieder schlauer …
https://docs.microsoft.com/de-de/powerquery-m/understanding-power-query-m-functions?WT.mc_id=DP-MVP-5004288
Das Schlüsselwort each wird verwendet, um mühelos einfache Funktionen zu erstellen. „each …“ ist syntaktischer Zucker für eine Funktionssignatur, die den _-Parameter „(_) => ….“ übernimmt.
Also einfach im Dialog „Benutzerdefinierte Spalte“ das „(_) =>“ weg lassen und schon funktioniert es .
Grüße
Marcus