Meiner Erfahrung nach, werden in vielen Unternehmen Organigramme/ Organisationsstrukturen manuell in Excel gepflegt. Häufig liegen diese in einer sog. unregelmäßigen Hierarchie vor, die in Power BI/ Power Pivot-Lösungen nicht ohne weiteres integriert werden können. Weil diese Daten jedoch meist als Dimension in meinen analytischen Modellen genutzt werden sollen, beschäftigt sich der vorliegende Artikel damit, wie Du „unregelmäßige Hierarchien“ in Power BI und Power Pivot nutzen solltest.
Als Abonnent meines Newsletters erhältst Du die Beispieldateien zu den Beiträgen dazu. Hier geht’s zum Abonnement des Newsletters!
Was sind unregelmäßige Hierarchien?
Die wohl am häufigsten vorkommende unregelmäßige Hierarchie ist die eines Organigramms. Das wesentliche Merkmal hierbei ist, dass die – ich nenne es mal – Baumtiefe nicht überall gleich ist. Während die Abteilung Controlling die 2. Ebene und gleichzeitig den Endpunkt dieses Hierarchiestrangs darstellt, stellt die Vertriebsregion Nord, Ost die 3. Ebene eines anderen Hierarchiestrangs dar.
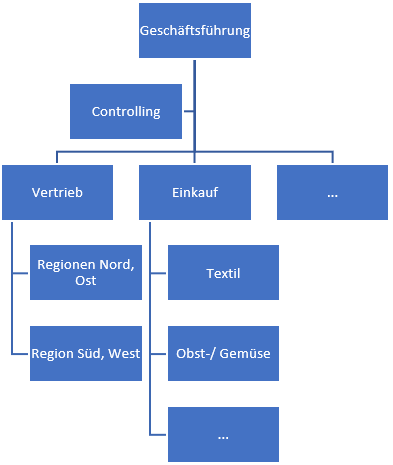
Diese Organisationsstruktur läßt sich in eine Tabelle übersetzen, die ich als Basis für mein Power BI-Datenmodell nutzen kann. Diese Tabelle sieht wie folgt aus:
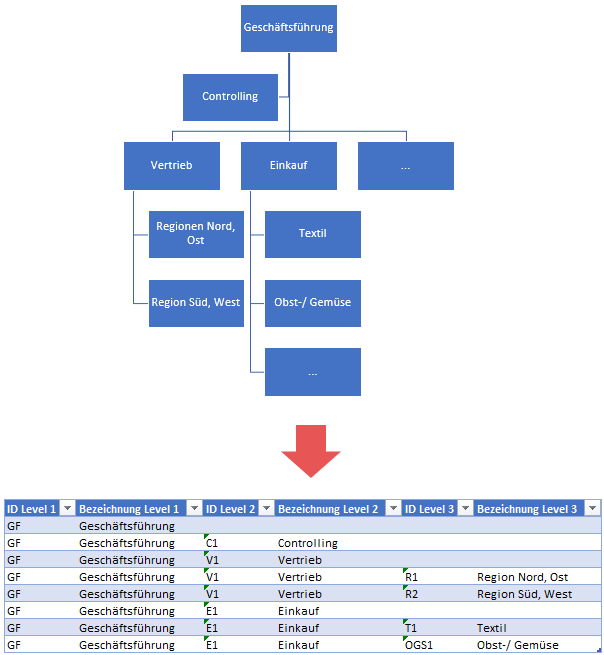
Ich kenne es aus Kundenprojekten, dass eine solche Tabelle – zumeist händisch in Excel gepflegt – als Datenbasis für weiterführende Berichte dient. Schauen wir uns an, wie ich diese Dimensionstabelle in mein Datenmodell integrieren kann.
Die Hierarchie mit der Faktentabelle verknüpfen
Eine Dimensionstabelle ist ohne zu aggregierende Fakten meist wenig wert. Für mein Beispieldatenmodell nehme ich eine fiktive Faktentabelle mit Zeitbuchungen je Organisationseinheit.
Die Faktentabelle
Diese sieht wie folgt aus:
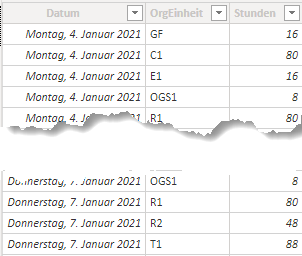
Die Struktur ist simpel:
- die Spalte Datum ordnet die gebuchte Zeit einem Tag zu,
- die Spalte OrgEinheit ordnet die gebuchte Zeit einer Organisationseinheit zu (mit dieser Spalte möchte ich nachher meine Tabelle mit der Organisationsstruktur verknüpfen) und
- die Spalte Stunden beinhaltet die zu aggregierenden Stundenbuchungen
Die Problematik: Wie erstelle ich die Beziehung zwischen den Tabellen?
Da die Dimensionstabelle die IDs der OrgEinheiten nicht in einer einzelnen, sondern in 3 Spalten vorliegen hat, ist das Erstellen einer funktionalen Beziehung zwischen beiden Tabellen schwierig.
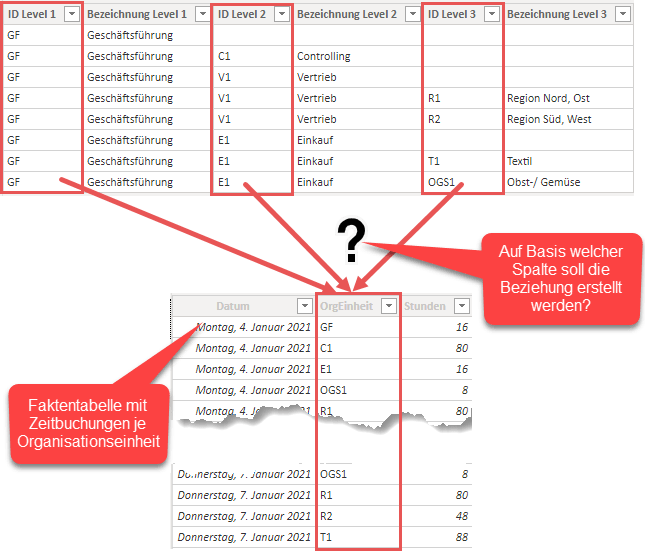
Meine Dimensionstabelle hat 3 potentielle Spalten zu bieten, auf deren Basis ich eine Beziehung mit den Fakten herstellen könnte. Aber zwischen 2 Tabellen kann es immer nur eine aktive Beziehung geben und diese muss zwischen exakt 2 Spalten existieren. Ich muss also eine Spalte in der Dimension erzeugen, die die ID des niedrigsten Elements beinhaltet, um auf dieser Basis die Beziehung erstellen zu können. Dies kann sowohl mit DAX als auch mit Power Query gelöst werden. Da ich ein großer Freund davon bin, alles was mit Datenmodellierung zu tun hat in Power Query zu lösen, mache ich hier keine Ausnahme.
Power Query to the recue: Eine Spalte mit den OrgIDs erstellen
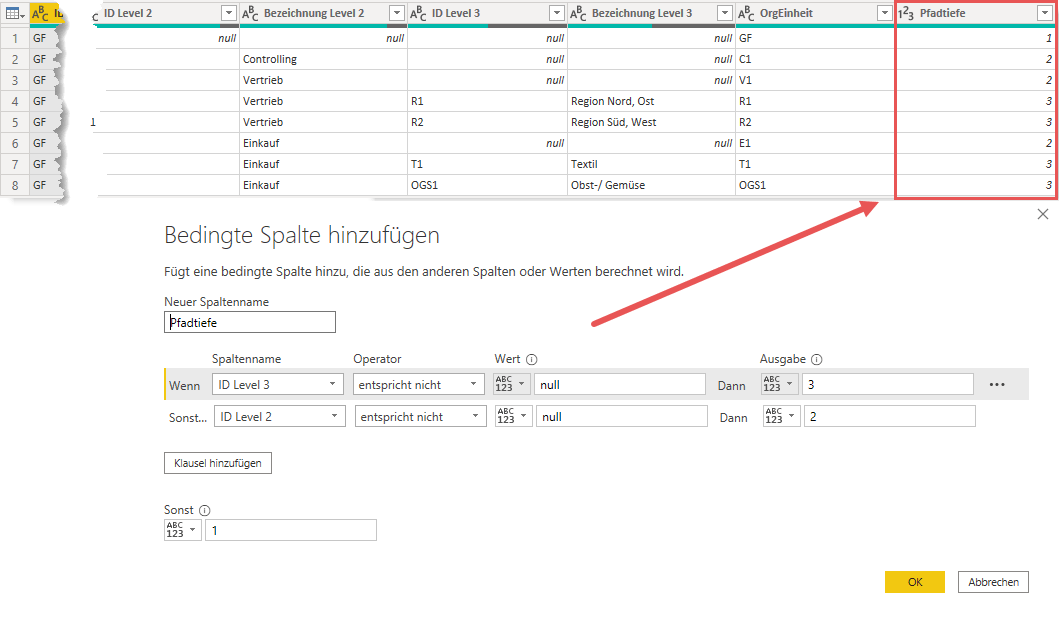
Die folgende Abbildung zeigt die Erstellung der Spalte OrgEinheit. Ich gehe einfach vom niedrigsten Hierarchie-Level (in meinem Falle Hierarchie-Level 3) rückwärts bis zum ersten Level durch und prüfe, ob der jeweilige Wert ungleich null (nicht zu verwechseln mit Null) ist. In diesem Fall ist dies das Element, dass ich in meiner neuen Spalte speichern möchte:
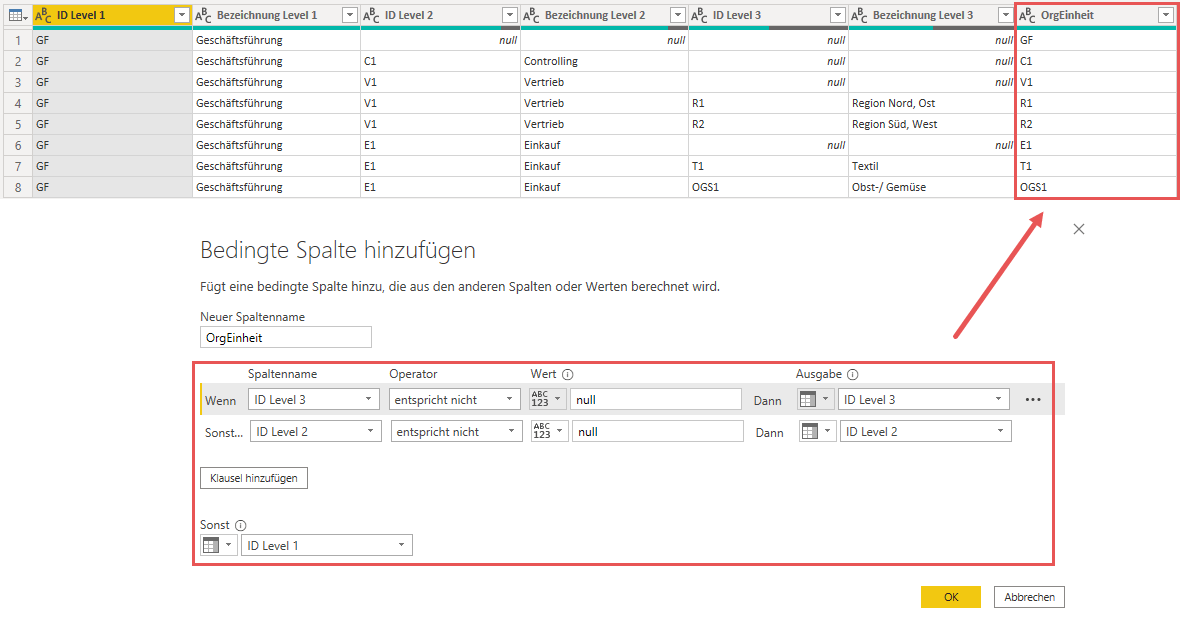
Damit haben wir jetzt die Spalte herausgebildet, auf deren Basis die Beziehung zwischen der Organisationsstruktur und den Zeitbuchungen hergestellt werden kann:
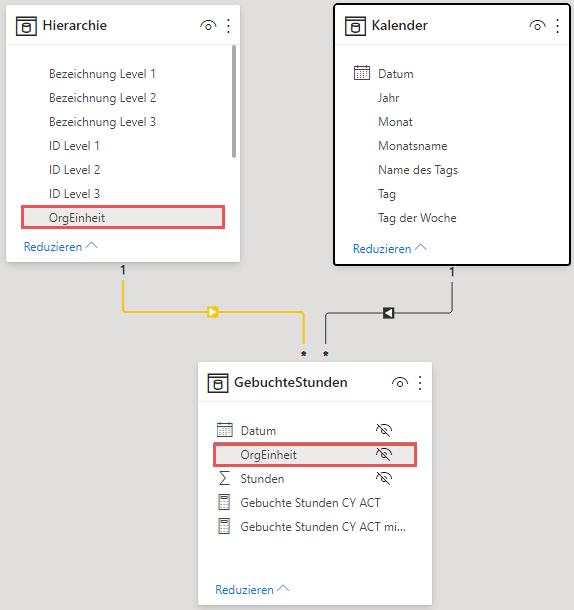
An dieser Stelle haben wir ein funktionierendes Datenmodell, das uns die Darstellung der folgenden Matrix ermöglicht:
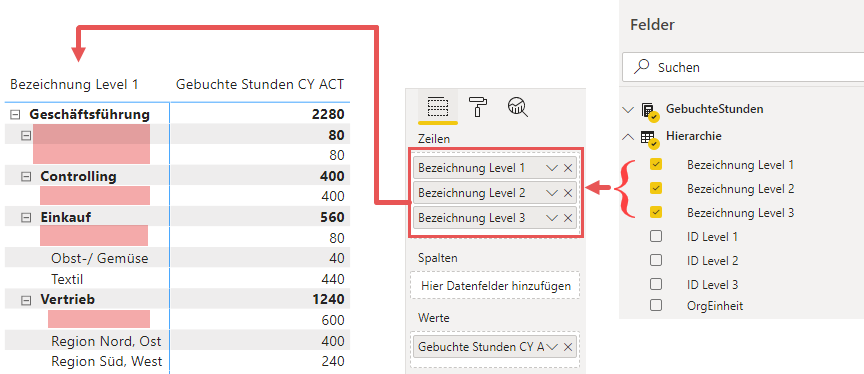
Die Matrix kalkuliert die korrekten Ergebnisse, jedoch sind die Leerwerte in den Zeilenbeschriftungen unschön. Diese ergeben sich dadurch, dass eben nicht alle Felder eines jeden Datensatzes innerhalb der Organisationsstruktur gefüllt sind:
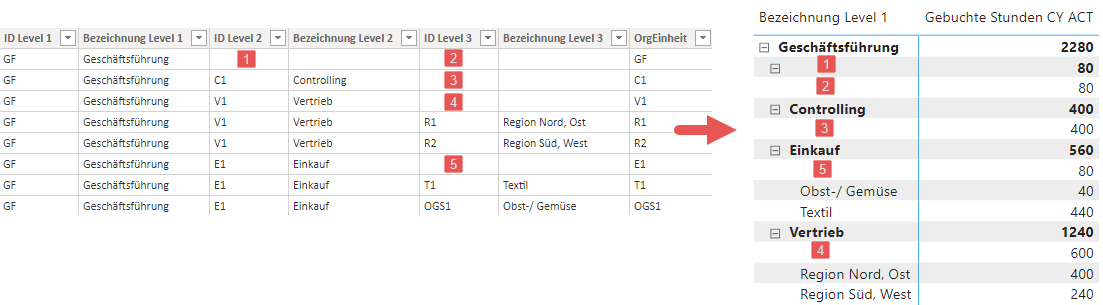
Als nächstes werde ich die unschönen Lücken der Tabelle beheben.
Vorarbeit im Datenmodell: Die Hierarchietabelle um die Spalte ‚Pfadtiefe‘ erweitern
Um die Lücken in der Matrix zu bekämpfen, gibt es ein wunderbares DAX Pattern unserer italienischen Freunde Marco und Alberto von SQLBI. (Hier geht’s zu meinen Podcast-Episoden mit Marco und Alberto). Bevor wir dieses jedoch umsetzen können, benötigt meine Hierarchie noch eine zusätzliche Spalte: Die Pfadtiefe. Auch diese berechne ich in Power Query. Die Logik ist hierbei die gleiche wie bei der OrgEinheit, nur dass ich mir nicht den Wert eines Feldes zurückgeben lasse, sondern eine Zahl, die das maximale ID Level des aktuellen Datensatzes widerspiegelt.
Mit dieser Hierarchie gewappnet, kann ich in die Darstellung im Bericht einsteigen.
Leere Zeilen im Bericht ausblenden
Um programmatisch zu entscheiden, ob ein nicht gefülltes Hierarchie-Level innerhalb einer Visualisierung (z. B. einer Matrix) ausgeblendet werden soll, muss ich zwei Informationen generieren:
- Welches ist die maximale Pfadtiefe der Hierarchie für das angezeigte Element und
- welches ist die aktuelle Position innerhalb des Hierarchie-Pfades in meiner Visualisierung.
Die beiden Measures – deren Erstellung ich gleich im Detail zeigen werde – sehen dann in einer Visualisierung wie folgt aus:
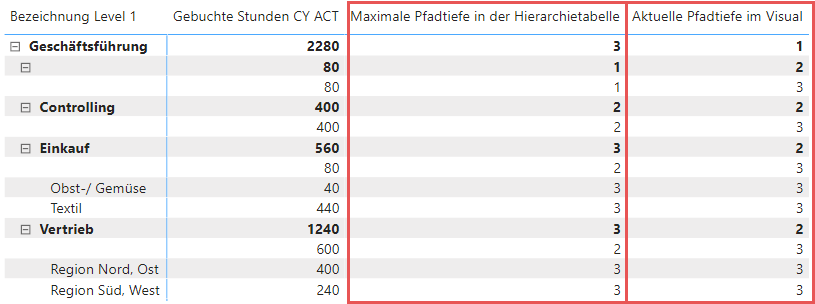
Für alle angezeigten Zeilen innerhalb der Matrix, deren Zeilenbeschriftung leer ist, kannst Du hier deutlich erkennen, dass der Wert „Aktuelle Pfadtiefe im Visual“ größer ist als der Wert „Maximale Pfadtiefe in der Hierarchietabelle“. Auf dieser Basis kann nachher das Ausblenden der ungewünschten Leerwerte stattfinden. Schauen wir uns nun die dafür notwendigen Measures an.
Measure #1: Die Ermittlung der maximalen Pfadtiefe
Die Kalkulation der maximalen Pfadtiefe findet auf Basis der Spalte Pfadtiefe in der Hierarchietabelle statt. Der DAX-Code hierfür ist simpel:
Maximale Pfadtiefe in der Hierarchietabelle =MAX ( Hierarchie[Pfadtiefe] )
Nun geht es darum, die im Visual aktuell vorliegende Pfadtiefe zu ermitteln.
Measure #2: Die Ermittlung der aktuellen Position innerhalb des Hierarchie-Pfades
Das folgende Measure ist statisch und muss händisch an die Anzahl an Ebenen angepasst werden, die ich als Zeilenbeschriftung einbaue. Ich habe in meinem Visual beispielsweise 3 Ebenen eingezogen:
Daher bezieht sich mein Measure auch auf eben diese 3 Ebenen. Sofern ich mehr Ebenen berücksichtigen möchte, muss ich mein Measure entsprechend anpassen. Hier das Measure, wie es Marco und Alberto in ihrem Pattern nutzen:
Aktuelle Pfadtiefe im Visual =ISINSCOPE ( Hierarchie[Bezeichnung Level 1] ) + ISINSCOPE ( Hierarchie[Bezeichnung Level 2] ) + ISINSCOPE ( Hierarchie[Bezeichnung Level 3] )Die INSCOPE()-Funktion gibt true zurück, sofern die als Parameter übergebene Spalte im Filterkontext enthalten ist. Da true = 1 und false = 0 kann man die Ergebnisse der Funktionsaufrufe addieren. Jetzt haben wir alle notwendigen Werkzeuge, um unsere Matrix optimal zu gestalten. Nutzen wir diese nun für das finale Measure:
Das finale Measure
Das Basis-Measure, welches die Stunden addierte, sieht wie folgt aus:
Gebuchte Stunden CY ACT =SUM ( GebuchteStunden[Stunden] )Gebuchte Stunden CY ACT mit unterdrückten leeren Hierarchiestufen =VAR Wert = [Gebuchte Stunden CY ACT]VAR bolZeigeZeilenbeschriftung = [Aktuelle Pfadtiefe im Visual] <= [Maximale Pfadtiefe in der Hierarchietabelle]VAR Ergebnis = IF ( bolZeigeZeilenbeschriftung = TRUE (), Wert, BLANK () )RETURN ErgebnisGebuchte Stunden CY ACT mit unterdrückten leeren Hierarchiestufen =VAR Wert = [Gebuchte Stunden CY ACT]VAR bolZeigeZeilenbeschriftung = [Aktuelle Pfadtiefe im Visual] <= [Maximale Pfadtiefe in der Hierarchietabelle]VAR Ergebnis = IF ( bolZeigeZeilenbeschriftung, Wert )RETURN Ergebnis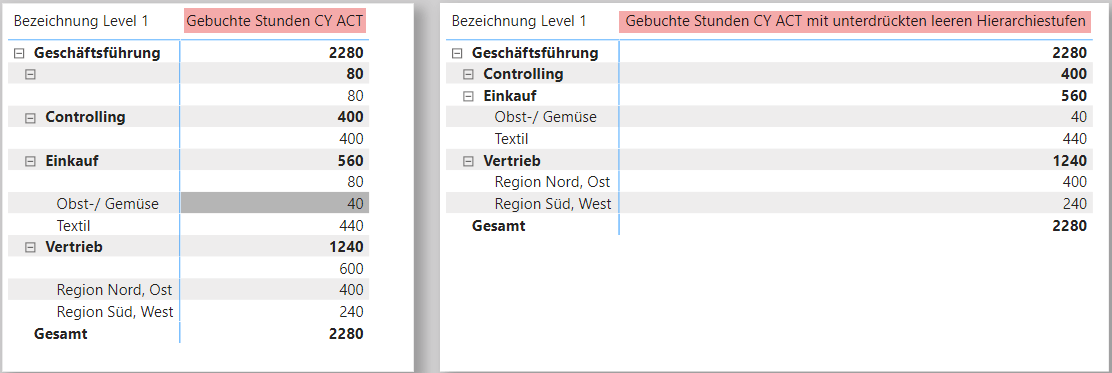
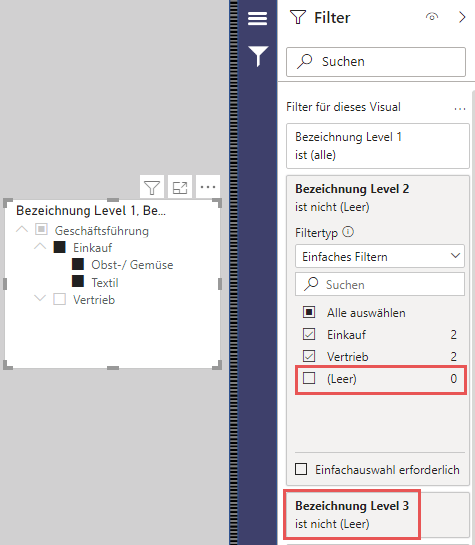
Leerwerte in Datenschnitten ausblenden
In der ersten Fassung dieses Artikels hatte ich auf den Hierarchy Slicer von Microsoft MVP Jan Pieter Posthuma verwiesen, um Leerwerte auszublenden. Alexander Robé hatte mich dann in den Kommentaren (siehe unten) darauf hingewiesen, dass das native FilterPane natürlich ebenfalls Filter auf den Datenschnitt setzen kann… Daher hier die denkbar einfachste aller Lösungen (an die ich nicht gedacht hatte). Danke Alex 🙂
Danke fürs Lesen und bis zum nächsten Mal. Und bitte denk daran: Sharing is caring. Wenn Dir der Beitrag gefallen hat, dann teile ihn gerne. Falls Du Anmerkungen hast, schreibe gerne einen Kommentar, oder schicke mir eine Mail an lars@ssbi-blog.de
Viele Grüße aus Hamburg,
Lars

Lars ist Berater, Entwickler und Trainer für Microsoft Power BI. Er ist zertifizierter Power BI-Experte und Microsoft Trainer. Für sein Engagement in der internationalen Community wurde Lars seit 2017 jährlich durch Microsoft der MVP-Award verliehen. Lies hier mehr…

Jonas meint
Hallo,
schöne Idee und gute Lösung! Ich bin auf den Beitrag gestoßen, weil ich ebenfalls ein Problem mit unregelmäßigen Hierarchien habe. Dabei werden allerdings teilweise auch Hierarchieebenen „übersprungen“, nämlich in der Strukturierung der Konten. Hier mal ein grober Abriss:
H1: Ergebnis (Erlöse, Aufwendungen, Umlagen)
H2: Kosten-/Erlösart
H3: Kontengruppe
H4: Kontenuntergruppe
H5: Konten
Da alles auf Konten verbucht wird, geht es natürlich immer runter bis auf H5. Eine Kosten-/Erlösart ist auch immer vorhanden, jedoch nicht immer eine Kontengruppe und/oder Kontenuntergruppe. Sprich, mitunter werden Hierarchieebenen „übersprungen“. Manchmal gibt es H1, H2, H5, manchmal H1, H2, H3, H5 und manchmal alle.
Wie würdest Du mit sowas umgehen?
Ich habe es nach Deinem Blogbeitrag versucht, indem ich in der Dimension für jede Hierarchieebene eine eigene Tabelle angelegt habe, Beziehungen teilweise deaktiviert und mit userelationship experimentiert. Aber leider ohne Erfolg.
Falls das für Dich eine spannende Herausforderung ist, würde ich mich freuen und bin gespannt, ob was bei rauskommt.
Beste Grüße
Jonas
Jonas meint
Hallo,
ich greife den Faden noch mal selbst auf. Für das von mir aufgeworfene Problem der „Lücken“ innerhalb der Hierarchiepfade habe ich tatsächlich keine Lösung gefunden. Hier habe ich in der Datenaufbereitung in Power Query dafür gesorgt, dass die Lücken geschlossen werden. Das führt unweigerlich dazu, dass innerhalb derselben Hierarchieebene inhaltlich unterschiedliche Dinge enthalten sind, lässt sich aber nicht vermeiden. Wenn es H1, H2 und H5 gibt, wird H5 eben zu H3 und H4 und H5 bleiben leer. Die Original-Spalten können natürlich erhalten bleiben, um je nach Verwendungszweck auf inhaltlich konsistente Spalten zurückgreifen zu können.
Mir ist aber aufgefallen, dass bei der im Blogpost dargestellten Variante ein Problem entsteht, wenn ein Visual bestimmte Hierarchieebenen nicht enthalten soll, z. B. wenn Level 1 und Level 2 weggelassen werden sollen. Dann kommt die statische Berechnung der aktuellen Pfadtiefe in die Quere. Deshalb hier eine Variante mit dynamischer Berechnung:
++++
Summe_mat =
var Wert=[Summe]
var akt_PT=isinscope(dim[L1])+ISINSCOPE(dim[L2])+ISINSCOPE(dim[L3])+ISINSCOPE(dim[L4])+ISINSCOPE(dim[L5])+ISINSCOPE(dim[L6])
var MaxPT=ISTEXT(IF(ISINSCOPE(dim[L1]), FIRSTNONBLANK(dim[L1], 1), BLANK()))+ISTEXT(IF(ISINSCOPE(dim[L2]), FIRSTNONBLANK(dim[L2], 1), BLANK()))+ISTEXT(IF(ISINSCOPE(sim[L3]), FIRSTNONBLANK(dim[L3], 1), BLANK()))+ISTEXT(IF(ISINSCOPE(dim[L4]), FIRSTNONBLANK(dim[L4], 1), BLANK()))+ISTEXT(IF(ISINSCOPE(dim[L5]), FIRSTNONBLANK(dim[L5], 1), BLANK()))+ISTEXT(IF(ISINSCOPE(dim[L6]), FIRSTNONBLANK(dim[L6], 1), BLANK()))
var showif=akt_PT<=MaxPT
return
If(showif=TRUE(), Wert, BLANK())
++++
Vielleicht hilft es ja dem ein oder der anderen. Für mich funktioniert es. Vielleicht gibt es aber auch elegantere Lösungen dafür…
Lars Diener meint
Hallo Lars,
danke für deinen Beitrag. Hat mir sehr geholfen. Ich habe aktuell nur das Problem, dass ich anstelle von Abteilungen unser Firmenorganigramm abbilde und PowerBI mit die Hierachie Ebenen addiert. Dies führt aber auf der obersten Ebene dann zu einem falschen Ergebnis, weil die Konsolidierung der Intercompany Beziehungen nicht in einer extra Gesellschaft erfolgt.
Beispiel:
Ebene 1 – Konzern gesamt
Ebene 2 – Business Unit 1, Business Unit 2
Ebene 3 – Gesellschaften xyz BU1, Gesellschaten abc BU 2
Die Gesellschaften der Ebene 3 dürfen nicht addiert werden sondern es muss der Code für Business Unit 1 abgerufen werden. Es geht um Finanz Cognos Daten. Jeder Gesellschaft hat ein eindeutigen Cognos Code.
Hoffe das war halbwegs verständlich und du hast vllt eine Idee wie man die Aufsummierung in einer Hierarchie verhindern kann.
LG Lars
Alexander Robé meint
Vielen Dank für den tollen Artikel, Lars!
Ich möchte den Hierarchy Slicer aber nur einschränkend empfehlen, da er in der Vergangenheit mehrfach Probleme verursacht hat (Versionierung, Performance…)
Meines Wissens nach bietet der PowerBI-integrierte Datenschnitt bereits die Möglichkeit, Leerwerte auszublenden.
Meine bislang immer zielführende Technik ist, direkt auf das Visual des Datenschnitts einen Filter zu legen.
Normalerweise das Measure „Gebuchte Stunden CY ACT „größer als 0 – in Deinem Fall evtl. sogar ausreichend die Spalte „GebuchteStunden[Stunden] “ ist nicht leer als Kriterium für das Visual festzulegen
Klar ist wieder eine Berechnung mehr, aber speziell die Spaltenvariante sollte relativ zügig rechnen und den Visual-Aufbau nur minimalst verzögern…
SG,
Alex
Lars Schreiber meint
Hi ALex,
danke für Deinen Kommentar. Die beiden von Dir angesprochenen Lösungsansätze funktionieren an dieser Stelle leider nicht, weil den Leerwerten in der Hierarchie ja tatsächlich Werte in der Faktentabelle entsprechen. „„Gebuchte Stunden CY ACT „größer als 0“, oder Leerwert in der Faktentabelle kommen somit nicht vor und können auch kein Filterkriterium sein. Aber Du hast natürlich vollkommen Recht, dass das FilterPane ein Lösungsansatz für den Slicer sein kann: Ich filtere hier einfach die Leerwerte aus (Lösungen können manchmal so einfach sein *facepalm). DANKE DIR 🙂
Viele Grüße,
Lars
Michael meint
Hallo Lars,
ich bin Dank Google auf deinen Blog gekommen, da ich im Prinzip das gleiche Problem mit Leerwerten im Standard Slicer habe. Der Erste Gedanke war auch ein einfaches herausfiltern der „null“ Werte, allerdings Fehlen dann bei Unregelmäßigen Hierarchien manche Einträgen auf den Mittleren Ebenen komplett. Da es hier keine Untere Ebene gibt.
Gibt es hierfür mittlerweile eine Andere Lösung?
Gruß Michael