Ein Leser meines Blogs kam vor kurzem mit folgender Frage auf mich zu:
Hast Du einen Tipp, wenn man CSV-Dateien aus einem Ordner lädt und eine Datei ist dabei, die eine Spalte mehr hat? In meinem Fall kann ich die neue Spalte nicht „nachladen“, obwohl alle anderen Überschriften gleich sind. Freue mich auf Deine Nachricht.
Lieber Thomas, ich hoffe mein heutiger Beitrag löst Dein Problem 🙂
Als Abonnent meines Newsletters erhältst Du die Beispieldateien zu den Beiträgen dazu. Hier geht’s zum Abonnement des Newsletters!
Die Problemstellung
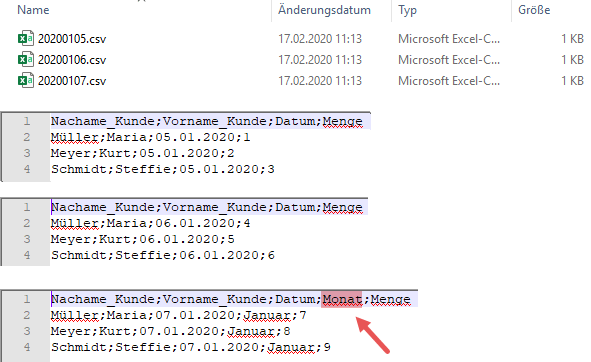
Um eine Beispiellösung zu erarbeiten habe ich drei csv-Beispieldateien erzeugt. In allen drei Dateien befindet sich die Überschrift in der ersten Zeile. Die Struktur aller Dateien ist identisch, jedoch mit einer einzigen Ausnahme: In Datei 20200107 wurde zwischen den beiden Spalten Datum und Menge die Spalte Monat eingefügt, die in den anderen beiden Dateien nicht vorhanden ist!
Die Datenbasis
Die Datenbasis für meine Beispiellösung sieht wie folgt aus: 3 csv-Dateien mit den abgebildeten Inhalten…
Schauen wir uns an, wie diese Dateien über den gewöhnlichen «Import aus Ordner» importiert würden.
Der „gewöhnliche“ «Import aus Ordner»
Das Importieren ganzer Ordner ist eine der großen Stärken von Power Query. Früher habe ich lange VBA-Skripte in Excel geschrieben, um diese Funktionalität zu erhalten. Natürlich ist der Import aus Ordnern generell nur dann sinnvoll, wenn die zu importierenden Dateien strukturgleich sind. Nur so ist es möglich, verschiedene Dateien durch dieselbe Power Query-Abfrage verarbeiten zu lassen, ohne im M-Skript zig Sonderfälle abfangen zu müssen. Aber sehen wir weiter… 😉
Um aus einem Ordner zu importieren, wähle ich den Datenquellentyp „Ordner“ aus und gebe den Pfad zum entsprechenden Ordner an:
Danach öffnet sich ein Dialog, der mich diese Daten sofort kombinieren oder laden lassen möchte. Hier gehe ich IMMER zuerst auf Daten transformieren, da ich immer erst sehen möchte, was Power Query intern aus dieser Abfrage machen möchte, bevor ich mich entschließe, diese zu kombinieren oder zu laden. Ich klicke hier also zuerst auf Daten transformieren:
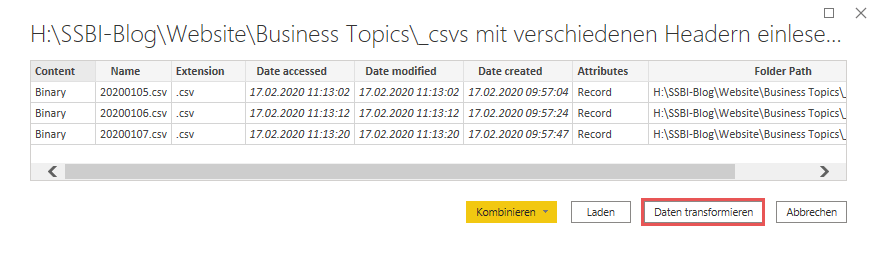
Danach bietet sich mir eine Sicht auf die Metadaten der Dateien des Ordners, die sowohl die Dateien selbst (im Binary-Format) beinhalten, als auch Informationen wie Name, Pfad zur Datei, etc. Über einen Filter auf der Spalte Extension stelle ich zunächst sicher, dass ich nur auf die csv-Dateien des Ordners zugreife. Es könnten sich ja durchaus auch andere Dateiformate im Ordner befinden.
Die Magie geschieht mit einem Klick auf den Doppelpfeil im Spaltenkopf der Spalte Content:

Nach dem Klick auf den Doppelpfeil, der den Befehl „Daten kombinieren“ anstößt, erscheint der Assistent für das Kombinieren der einzelnen Dateien des Ordners. Die folgende Abbildung zeigt zwei Screenshots, die sich durch eine verschiedene Auswahl in Punkt 1 – Wahl der Beispieldatei – voneinander unterscheiden:
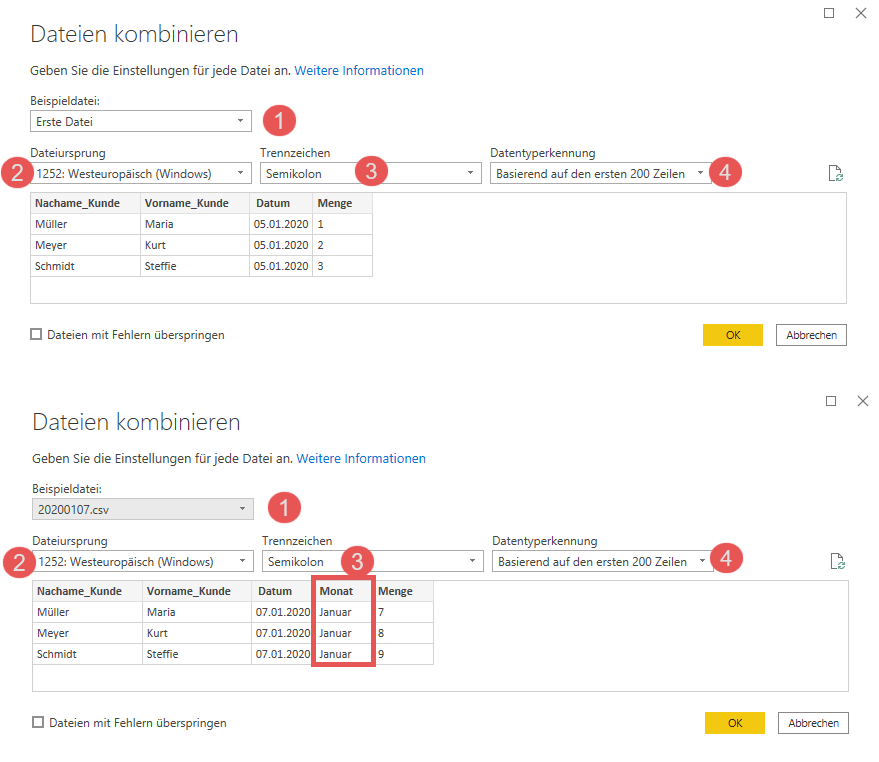
Hier eine kurze Erklärung zu den einzelnen Punkten des Assistenten:
- Beispieldatei: Hier habe ich die Möglichkeit generell die „Erste Datei“ des Ordners zu wählen, oder – wie im Schritt 1 des unteren Bereichs des Screenshots – eine dedizierte Datei als Beispieldatei zu wählen.
- Dateiursprung: Hier kann ich definieren, in welcher Sprache und auf welchem Betriebssystem die zu importierenden Dateien erstellt wurden. Dadurch kann dann beispielsweise interpretiert werden, ob es sich bei 03/02/2020 um den 03. Februar, oder den 02. März 2020 handelt. Mehr Informationen hierzu findest Du hier.
- Trennzeichen: Definiert, durch welches Trennzeichen Spalten voneinander getrennt sind.
- Datentypenerkennung: Hier kann ich festlegen, ob die automatische Datentypenerkennung von Power Query auf Basis der ersten 200 Zeilen, dem gesamten Dataset, oder überhaupt nicht stattfinden soll.
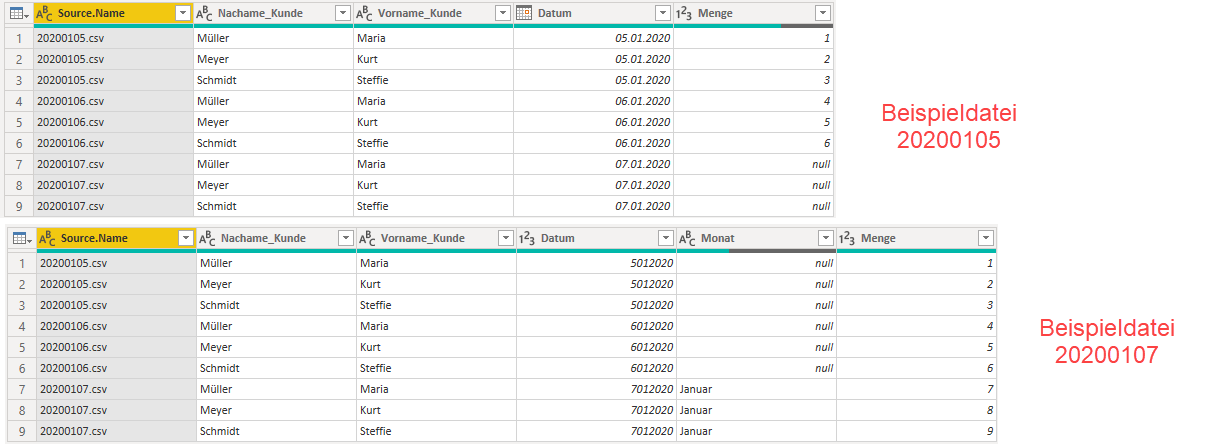
Hier die Ergebnisse, wenn ich entweder die Datei 20200105 oder die Datei 20200107 (also die Datei, die als einzige zusätzlich die Spalte Monat enthält) als Beispieldatei wähle:
Beim Blick auf den Screenshot kann man folgendes bemerken:
- Wähle ich die Datei 20200107 als Beispieldatei, dann bekomme ich genau das gewünschte Ergebnis. Die Spalte Monat ist enthalten, hat für die Datei 20200107 den Wert Januar, und für die anderen Dateien (in denen diese Spalte gar nicht existiert), den Wert null. So soll es sein!
- Mit der Datei 20200105 als Beispieldatei sieht es jedoch etwas anders aus. Hier werden die beiden strukturgleichen Dateien 20200105 und 20200106 vollständig geladen. Jedoch ergeben sich für die Datei 20200107 zwei Probleme:
- Die Spalte Monat wurde nicht importiert.
- In Spalte Menge stehen ausschließlich null-Werte, obwohl in der Ursprungsdatei die Werte 7,8 und 9 enthalten waren.
Was ist hier passiert?
Bei der Auswahl der Beispieldatei speichert Power Query nicht nur die von mir definierten Werte für Dateiursprung, Trennzeichen und auf Basis wie vieler Datensätze die Datentypenerkennung vorgenommen werden soll, sondern auch die Anzahl der Spalten, die beim Import zu erwarten sind. Dies geschieht durch die intern aufgerufene Funktion Csv.Documents() und sieht mit der Beispieldatei 20200105 wie folgt aus:
Csv.Document(Parameter1,[Delimiter=";", Columns=4, Encoding=1252, QuoteStyle=QuoteStyle.None])
Diese Funktion speichert automatisch (ohne mein Zutun), dass von jeder der kommenden csv-Dateien exakt 4! Spalten zu erwarten sind. Es werden aus der Datei 20200107 also die 4 Spalten Nachname_Kunde, Vorname_Kunde, Datum und Monat übernommen, nicht jedoch die Spalte Menge. Diese Spalten werden im Anschluss an die bereits importierten Tabellen der Dateien 20200105 und 20200106 angefügt. Die Spalten Nachname_Kunde, Vorname_Kunde und Datum können problemlos angefügt werden. Jedoch kann die Spalte Monat nicht an die Spalte Menge angefügt werden. Daher kommt es hier zu den 3 null-Werten in der Spalte Menge.
Die eigentliche Problematik dieser Vorgehensweise von Power Query ist also, dass es versucht auf Basis der Struktur einer einzigen csv-Datei, auch alle anderen Dateien zu behandeln. Generell ist dies vollkommen sinnvoll, denn ich sollte immer nur dann ordnerweise Dateien importieren, wenn ich sichergehen kann, dass diese strukturgleich sind. Für den Falls, dass ich jedoch weiß, dass hier und da mal eine neue Spalte auftaucht, aber nicht voraussehen kann, zeige ich jetzt eine simple Lösung.
Die Lösung
Die Lösung der Problemstellung ist erschreckend einfach. Allerdings muss ich mir hierfür zunächst eine Frage beantworten: Was bedeutet eigentlich der Abfrage-Ordner «Hilfsprogrammabfragen»?
Der Abfragen-Ordner «Hilfsprogrammabfragen»?
Beim Import aus Ordner, wird der Abfrage-Ordner «Hilfsprogrammabfragen» automatisch durch Power Query angelegt und mit Leben gefüllt.
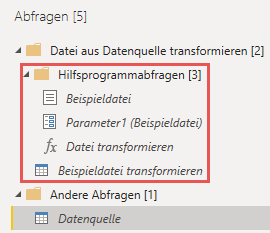
Die darin befindlichen 4 Elemente, erfüllen die folgenden Aufgaben…
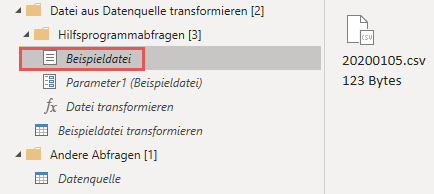
Beispieldatei
Bei diesem Element handelt es sich um diejenige Datei aus meinem Ordner, die ich beim Importdialog als Beispieldatei definiert habe. Sie ist die Basis für die Erstellung der Funktion Datei transformieren, die nachher auf alle zu importierenden Dateien angewandt wird.
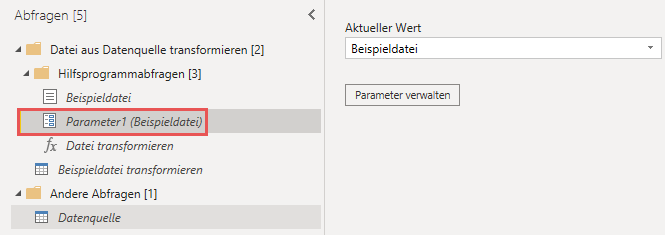
Parameter1 (Beispieldatei)
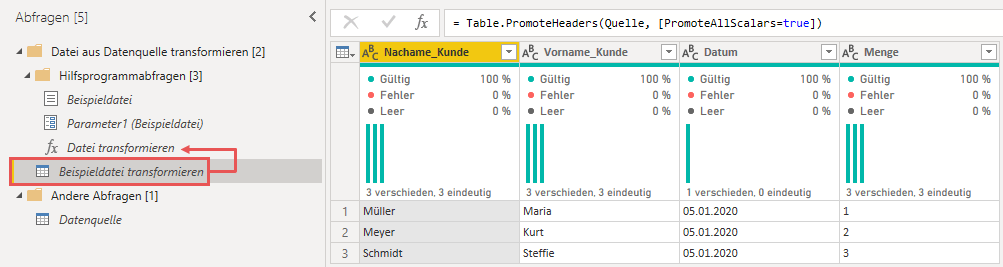
Der Parameter ein ist ein Verweis auf die Beispieldatei. Er wird in der Abfrage Beispieldatei transformieren verwendet. Ich gehe weiter unten auf die Details ein.
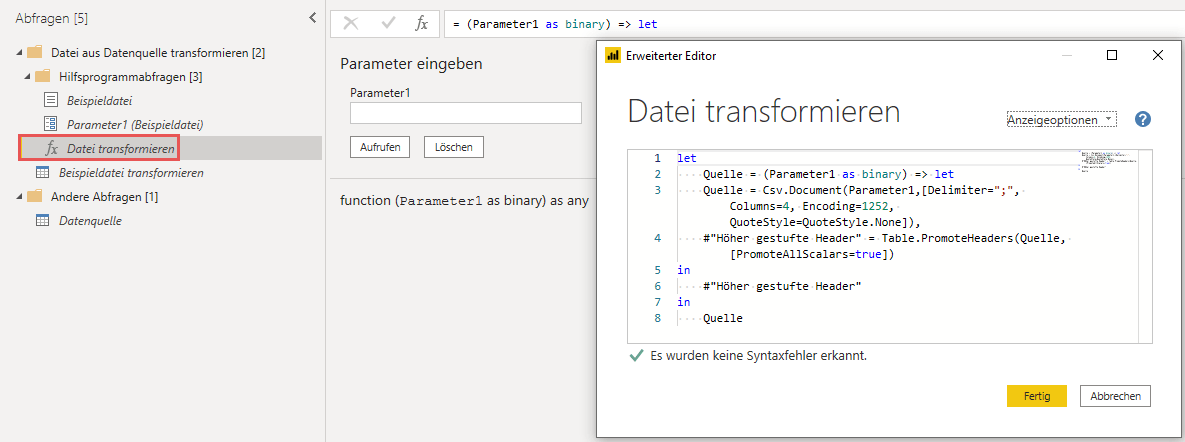
Datei transformieren
Diese Funktion wird ebenfalls automatisch beim Import aus Ordner erstellt und dies anhand der gewählten Beispieldatei. Auf Basis dieser Funktion werden alle Dateien des Ordners importiert. Was hier definiert wird, wirkt sich also auf alle Importe aus.
Beispieldatei transformieren
Wenn ich also beeinflussen möchte, wie die Dateien des Ordners importiert werden, liegt es wohl nahe, die Funktion Datei transformieren anzupassen, richtig?. Ja und nein. Ja, die Funktion muss angepasst werden. Da das manuelle Anpassen des M-Codes jedoch die meisten Power Query-Nutzer überfordern dürfte, hat das Power Query-Team eine Möglichkeit geschaffen, die Funktion anzupassen, ohne dabei im Quellcode rumwühlen zu müssen. Und dies geschieht über die Abfrage Beispieldatei transformieren. Sobald ich Änderungen an der Abfrage Beispieldatei transformieren vornehme, wird diese Änderung sofort in die Funktion Datei transformieren übernommen. Will ich also die Funktion beeinflussen/ verändern, sollte ich diese Abfrage entsprechend anpassen!
Nachdem jetzt die Bedeutung und Aufgabe der einzelnen Ordner-Elemente klar ist, ist die Lösung ziemlich simpel.
Der finale Schritt
Ich hatte weiter oben schon erwähnt, dass die feste Codierung der zu importierenden Spalten (Columns=4) das eigentliche Problem beim Import ist. Da dieser Parameter ein optionaler Parameter der Funktion Csv.Document() ist, kann ich diesen einfach weglassen. Danach ist der Import nicht mehr auf die 4 definierten Spalten festgeschrieben. Ich entferne diesen Parameter einfach aus der Abfrage Beispieldatei transformieren. Diese Änderung zieht sich in die Funktion Datei transformieren durch und das Ergebnis sieht wie gewünscht aus:

Bis zum nächsten Mal und denk dran: Sharing is caring. Wenn Dir der Beitrag gefallen hat, dann teile ihn gerne. Falls Du Anmerkungen hast, schreibe gerne einen Kommentar, oder schicke mir eine Mail an lars@ssbi-blog.de
Viele Grüße aus Hamburg,
Lars

Lars ist Berater, Entwickler und Trainer für Microsoft Power BI. Er ist zertifizierter Power BI-Experte und Microsoft Trainer. Für sein Engagement in der internationalen Community wurde Lars seit 2017 jährlich durch Microsoft der MVP-Award verliehen. Lies hier mehr…

Erdem meint
Erstmal vielen Dank für die Lösung. Allerdings habe ich das Problem mit PDF´s immernoch.
Da steht dann nicht columns=4, und bei 31 PDF Dateien kommt immerwieder mal vor, dass mal eine Spalte mehr drin ist. Power Query schneidet mir die Zeile dann einfach ab und es fehlen die Daten der Spalte.
Gibt es auch so eine Lösung wie oben auch für PDF Dateien?
Fischi_VIECH meint
Danke !! Hatte das Problem das bei manchen Dateien die erste Spalte nicht eingelesen wird, nur bei der Vorschaudatei, egal welche Datei ich dann wählte. So hat es auf jeden Fall geklappt!
Lars Schreiber meint
Schön, dass ich helfen konnte 🙂