In einem kleinen Kundenprojekt wurde ich vor kurzem mit einer Problemstellung konfrontiert, die hervorragend dafür geeignet ist, die Funktionsweise von Power Query zu erläutern. Sieh Dir an, wie ich mit Power Query auf einfache Art und Weise fortlaufende Zähler je Kostenstelle erzeugen kann.
Als Abonnent meines Newsletters erhältst Du die Beispieldateien zu den Beiträgen dazu. Hier geht’s zum Abonnement des Newsletters!
Die Zielstellung
Die Zielstellung ist, aus der linken blauen Tabelle, die rechte grüne Tabelle er erzeugen:
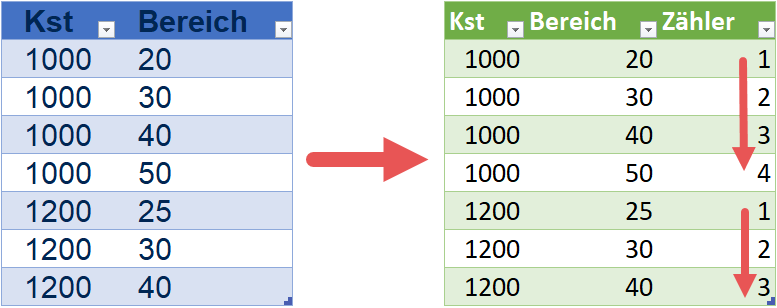
Inhaltlich muss ich dabei auf folgendes achten:
- Die Zieltabelle soll nach Kostenstelle und Bereich sortiert sein
- Die neue Spalte „Zähler“ soll eine fortlaufende Nummer erzeugen, die je Kostenstelle erneut bei 1 beginnt.
Es gibt wie immer viele unterschiedliche Wege, die zum Ziel führen. Schauen wir uns gemeinsam meinen Lösungsansatz an.
Die Lösung
Meine Lösung enthält in Power Query 10 unterschiedliche Schritte. Ich gehe jetzt auf die wesentlichen davon ein.
Das Sortieren der Spalten
Nachdem die Basistabelle in Power Query geladen wurde, sortiere ich zunächst die Spalten Kst und Bereich. Hierbei ist die richtige Reihenfolge der Sortierung wichtig. Im folgenden Screenshot kannst Du an den markierten Ziffern 1 und 2 erkennen, dass zuerst die Spalte Kst sortiert wurde und im Nachgang die Spalte Bereich. Dies stellt sicher, dass alle gleichen Kostenstellen ohne Unterbrechung zusammenstehen und die Bereiche aufsteigend innerhalb ihrer Kostenstelle vorkommen.
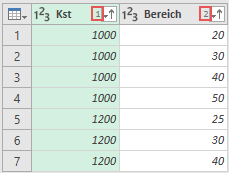
Nachdem die Sortierung sichergestellt ist, folgt nun die erste Hilfsspalte.
Neue Spalte: Fortlaufenden Index hinzufügen
Über Spalte hinzufügen → Indexspalte → Von 0 füge ich eine neue Spalte hinzu, die eine fortlaufende Nummer für jede Zeile der Tabelle erzeugt. Dieser Index berücksichtigt den Wechsel von Kostenstellen explizit nicht.
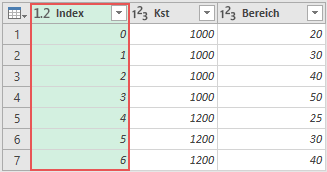
Diese Indexspalte allein ist wenig hilfreich. In Kombination mit dem folgenden Schritt, wirst Du die Sinnhaftigkeit erkennen.
Neue Spalte: Ermittlung des ersten Auftretens der jeweiligen Kostenstelle
Die eben erzeugte Indexspalte ermöglicht das Identifizieren einer jeden Zeile innerhalb der Tabelle. Damit ich jedoch den gewünschten fortlaufenden Zähler je Kostenstelle ermitteln kann, erzeuge ich eine weitere Hilfsspalte über die Funktion: List.PositionOf(#"Hinzugefügter Index"[Kst], [Kst]).

Diese Spalte ist der eigentliche Knackpunkt der Lösung. Daher erkläre ich kurz, was hier geschieht:
- Allgemeine Erklärung der Funktion List.PositionOf(): List.PositionOf() ist eine Funktion, die in ihrer kürzesten Form die folgende Syntax hat:
List.PositionOf(list as list, value as any) as any. Im ersten Argumentlistübergebe ich der Funktion eine Liste an Werten. Innerhalb dieser Liste kann ich dann nach der Position des zweiten Argumentsvaluesuchen. Tritt dieser Wert gar nicht auf, so erhalte ich den Wert -1, ansonsten wird mir die null-basierte Position des Wertes innerhalb der Liste zurückgegeben. - Ermittlung des zweiten Arguments
value: Value ist das Argument welches besagt, welchen Wert wir in der Liste suchen wollen. Innerhalb einer kalkulierten Spalte in Power Query, kann ich einfach mit[Kst]auf den aktuellen Zeilenwert der Spalte Kst verweisen. Somit ist[Kst]mein Wert für das Argumentvalue. - Ermittlung des ersten Arguments
list: Das erste Argument ist weniger intuitiv zu referenzieren. Daher beschreibe ich es erst an zweiter Stelle. Um die Liste zu referenzieren, in welcher die erste Position des aktuellen Zeilenwertes für [Kst] gesucht werden soll, muss ich den Namen des letzten Power Query-Schrittes wählen und diesem die Spaltenbezeichnung in eckigen Klammern hinten anstellen. In meinem Beispiel sieht das so aus:#"Hinzugefügter Index"[Kst].Falls Dich der Umgang mit Listen tiefgehender interessiert, empfehle ich Dir meinen englischsprachigen Artikel über Listen.
Da auch diese Spalte eine reine Hilfsspalte ist, komme ich nun zum schlussendlichen Ziel: Der Zählerspalte.
Die finale Zählerspalte erzeugen
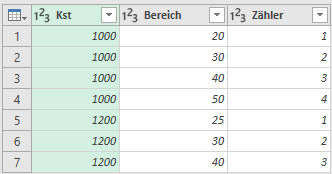
Wenn Du einen genauen Blick auf die Spalten Index und Hilf wirfst, wirst Du schnell erkennen, dass die Differenz beider Spalten +1 exakt das ist, was wir für unsere Lösung benötigen:
![Die Differenz der Spalten [Index] und [Hilf] ergibt das gewünschte Ergebnis, Power Query, Power BI](https://ssbi-blog.de/wp-content/uploads/2019/09/05-Die-finale-Zählerspalte.png)
Ich hoffe, dass diese Lösung für Dich nützlich ist 🙂
Bis zum nächsten Mal und denk dran: Sharing is caring. Wenn Dir der Beitrag gefallen hat, dann teile ihn gerne. Falls Du Anmerkungen hast, schreibe gerne einen Kommentar, oder schicke mir eine Mail an lars@ssbi-blog.de
Viele Grüße aus Hamburg,
Lars

Lars ist Berater, Entwickler und Trainer für Microsoft Power BI. Er ist zertifizierter Power BI-Experte und Microsoft Trainer. Für sein Engagement in der internationalen Community wurde Lars seit 2017 jährlich durch Microsoft der MVP-Award verliehen. Lies hier mehr…

Wilfried Schäfer meint
Hi Lars,
Warum hast du nicht einfach nur nach Kostenstelle gruppiert und dann in die gruppierte Tabelle einen Index eingefügt?
let
Source = Excel.CurrentWorkbook(){[Name=“Tabelle1″]}[Content],
Gruppierung_Kst = Table.Group(Source, {„Kst“}, {{„Alle“, each _, type table [Kst=nullable number, Bereich=nullable number]}}),
Index_in_Gruppierung = Table.AddColumn(Gruppierung_Kst, „Zähler“, each Table.AddIndexColumn([Alle], „Zähler“, 1, 1)),
Expand_Gruppierung = Table.ExpandTableColumn(Index_in_Gruppierung, „Zähler“, {„Bereich“, „Zähler“}, {„Bereich“, „Zähler.1“}),
Delete_not_needed = Table.RemoveColumns(Expand_Gruppierung,{„Alle“})
in
Delete_not_needed
Lars Schreiber meint
Hi Wilfried,
die Antwort auf Deine Frage lautet: Weil mir nicht immer der eleganteste Lösungsweg einfällt 😉 Deine Lösung gefällt mir auch besser. Danke für Deinen Kommentar.
Viele Grüße,
Lars
Anna-Maria Fenn meint
Grüß Euch,
vielen Dank Euch beiden! Ich hab‘ richtig viel aus den Beispielen gelernt.
Dabei kam ich noch auf eine sogar kürzere (und vermutlich etwas Ressourcen-sparendere) Variante:
let
Source = Excel.CurrentWorkbook(){[Name=“Tabelle1″]}[Content],
Gruppierung_Kst = Table.Group(Source, {„Kst“}, {{„Alle“, each _, type table [Kst=nullable number, Bereich=nullable number]}}),
Mit_Index = Table.Combine( Table.TransformRows(Gruppierung_Kst, each Table.AddIndexColumn(_[Alle], „Zähler“, 1, 1) ) )
in
Mit_Index
Viele Grüße,
Anna-Maria
Anna-Maria Fenn meint
Oder doch wieder ohne Gruppierung 🙂
Dafür muss das Gruppierungsmerkmal Kst jetzt wieder sortiert sein.
Diese nachfolgende Lösung ist jetzt möglicher Weise die schnellste Variante? (evtl. geht noch was mit Buffern)
Die List.Generate-Funktion ist noch so eine kürzliche Entdeckung, die meinen Blick auf mögliche Lösungsansätze total verändert hat.
let
Source = Excel.CurrentWorkbook(){[Name=“Tabelle1″]}[Content],
GruppenIndex = Table.FromRecords( List.Generate(
() => [ Zähler = 1, Merkmal = Source[Kst]{0}, i = 1],
each [i] <= Table.RowCount(Source),
each [ Zähler = if [Merkmal]=Source[Kst]{[i]} then [Zähler]+1 else 1 , Merkmal = Source[Kst]{[i]}, i = [i]+1 ],
each Source{[i]-1} & [Zähler = [Zähler]]
) )
in GruppenIndex
Anna-Maria Fenn meint
Jetzt hab ich gemessen – und wurde sehr überrascht: diese List.Generate-Methode ist viel langsamer als die beiden anderen mit Table.Group (von denen meine Variante die schnellere ist). M-Code ist dann wohl doch erheblich lahmer als eingebaute Funktionen …
So, Nachtschicht endet und ich lasse das Thema jetzt auch mal ruhen 😉
Andrea Kerlin meint
Hallo,
vielen Dank für diesen wertvollen Tip.
Ich bin maximal begeistert 🙂
Katharina meint
Danke für die Anleitung! Ich hab damit was zwar nicht lösen können (zu viele Zeilen und ein bereits im Ablauf dynamisch erzeugter Key, da dauert das List.PositionOf STUNDEN), aber den richtigen Impuls bekommen.
Lars Schreiber meint
Hallo Katharina,
ja, bei größeren Datenmengen können List-Operationen teilweise sehr lange dauern und sie sind dann natürlich nicht mehr zu empfehlen. Schön, dass Dir dieser Beitrag trotzdem helfen konnte.
Danke für Dein Feedback und viele Grüße aus Hamburg,
Lars
Basti meint
Hallo,
ich habe eine Tabelle mit rund 5000 Zeilen; dementsprechend lange dauert das berechnen der List.PositionOf-Spalte.
Tipp. -> Table.Buffer bzw. List.Buffer nutzen!. Ich habe folgenden Schritt ergänzt
[…]
Index = Table.AddIndexColumn(#“Umbenannte Spalten“, „Index“, 0, 1),
Sort = Table.Buffer(Table.Sort(Index,{{„Index“, Order.Ascending}})),
CustCol = Table.AddColumn(Sort, „Hilf“, each List.PositionOf(Sort[Kst],[Kst])),
CustColB = Table.AddColumn(CustCol, „Zähler“, each [Index]-[Hilf]+1),
[…]
Lars Schreiber meint
Hallo Basti,
ja, die Buffer halten einen Snapshot der Daten im RAM und greifen nicht immer auf die Basisdaten zurück. Das zu erklären, war für den vorliegenden Artikel ein wenig „too much“ 😉
Danke für den Hinweis und viele Grüße,
Lars
Basti meint
Ja, verstehe ich, aber einen Hinweis a la „Achtung, PositionOf kann laaaange dauern und Abhilfe könnte Buffer liefern (als Stichwort für Google 😉 wäre ja ne Möglichkeit
Susanne Lubina meint
Hallo Lars, das war Gedankenübertragung- genau das habe ich gestern gesucht, um neue Inventarnummern fortlaufend innerhalb eines Kontos zu erzeugen… vielen Dank, jetzt hab ich die Lösung!! Viele Grüße Susanne
Lars Schreiber meint
Hallo Susanne,
freut mich sehr, dass mein Artikel hilfreich war 🙂
Danke fürs Lesen und Dein Feedback.
Liebe Grüße,
Lars