Ich habe die Situation mehr als einmal erlebt, dass ich eine tagesbasierte Datenbasis als kumulierte Werte und nicht als tagesbasierte Einzelwerte erhalten habe. Dies ist gerade im Hinblick auf die Erstellung eines Datenmodells in Power Pivot oder Power BI Desktop häufig nicht hilfreich. Daher gehe ich im aktuellen Beitrag darauf ein, wie ich mit Power Query Tageswerte aus kumulierten Werten berechnen kann.
Als Abonnent meines Newsletters erhältst Du die Beispieldateien zu den Beiträgen dazu. Hier geht’s zum Abonnement des Newsletters!
Die Ausgangssituation
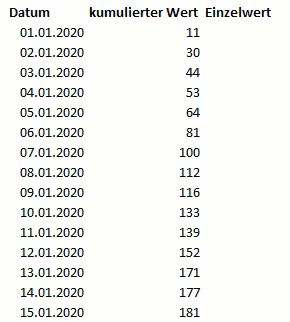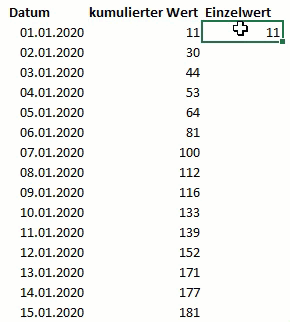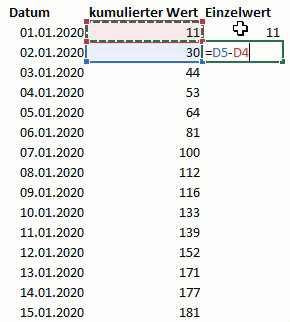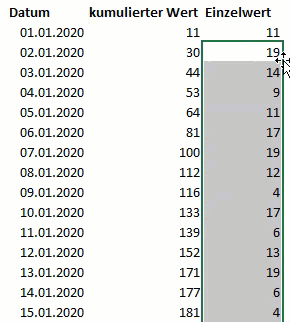
Die Datenbasis besteht (aus Vereinfachungsgründen) aus den beiden Spalten Datum und kumulierter Wert. Für jeden Tag wird die Summe aller Werte bis einschließlich diesem Tag ausgewiesen. Der Wert für den 03.01.2020 (44) ist also nicht der Wert für den 03.03.2020, sondern die Summe der Werte vom 01.01. bis einschließlich 03.01.2020.
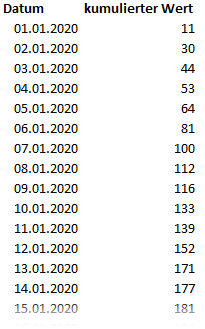
Diese Darstellung kann in einigen Fällen sinnvoll sein, ist in Bezug auf die Datenmodellierung in Power Pivot und/ oder Power BI Desktop häufig jedoch nicht optimal. Schon allein die Darstellung der je Tag erzeugten Werten in einer simplen Visualisierung (z. B. Balkendiagramm) kann hier nicht ohne weiteres erfolgen. Daher liegt es hier nahe, beim Import der Datenbasis diese bereits auf Tageseinzelwerte umzustellen. In Excel selbst, wäre dies relativ einfach…
Eine Lösung mit Excelformeln
Die folgende Animation zeigt, was Du wahrscheinlich längst schon weißt: Wie man diese Problematik in Excel mittels Formeln lösen würde…
In Power Query ist es jedoch nicht ohne weiteres möglich, sich auf die „Zelle darüber“ bzw. „darunter“ zu beziehen. Daher zeige ich hier einen Weg, wie dies bewerkstelligt werden kann.
Eine Lösung in Power Query
Die Vorgehensweise in Power Query weicht von der mittels Excelformeln ab. Aus didaktischen Gründen zerlege ich die Lösung in die folgenden Teilschritte…
Chronologisches Sortieren
Um sicherzustellen, dass sich die Tage in einer chronologischen Reihenfolge befinden, sortiere ich diese zu beginn aufsteigend.
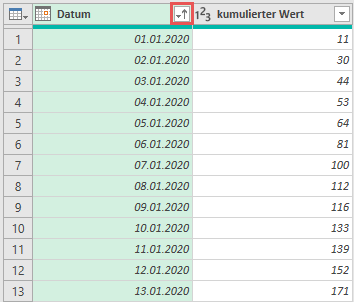
Auf diese Weise kann ich sicherstellen, dass sich der Vorgänger immer direkt über dem aktuellen Tag befindet.
Hinzufügen der Indices/ Indexe für den aktuellen und den Vorgängerdatensatz
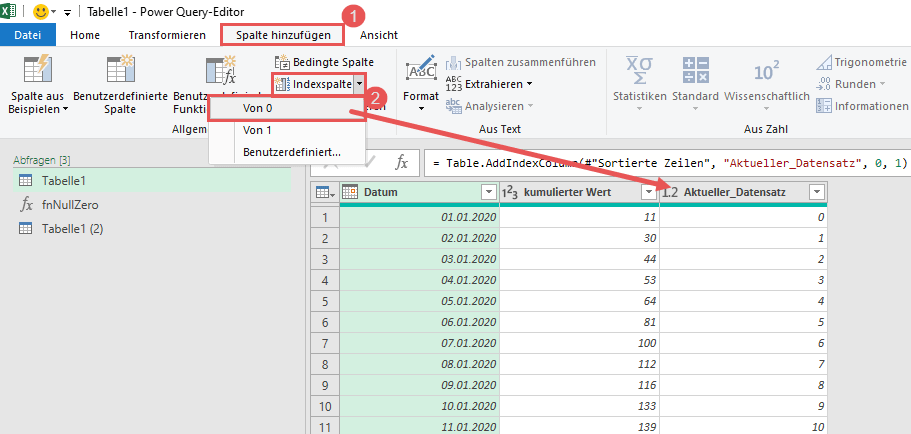
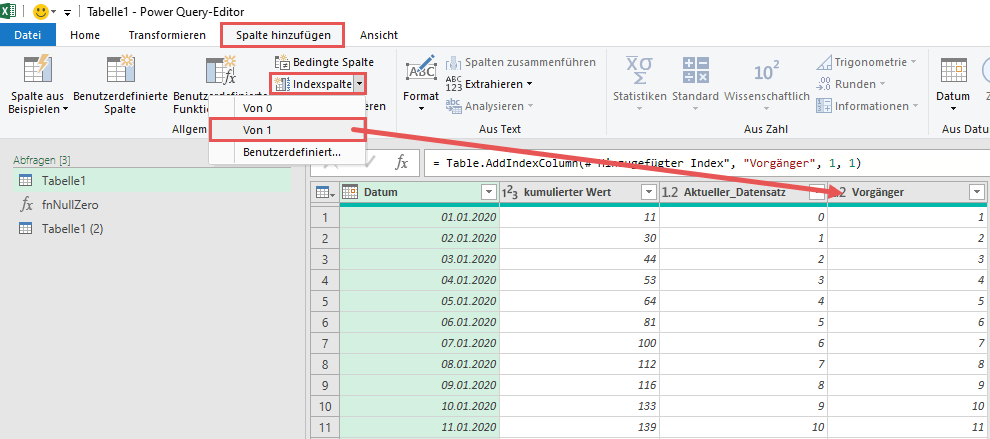
Nun erzeuge ich zwei Index-Spalten, die mir die Arbeit im weiteren Lösungsansatz stark erleichtern werden. Ich werde beide Spalten für einen sog. Self-Join nutzen und Du wirst im weiteren Verlauf sehen, was dies bedeutet:
Mit diesen beiden Spalten als Vorbereitung, kann ich endlich meinen Self-Join durchführen.
Join über die beiden Index-Spalten
Falls Du Dich bis hierher gefragt hast, was es denn nun mit diesen Index-Spalten auf sich hat, kann ich Dich nun beruhigen. Es folgt die Auflösung des Rätsels:
Die beiden Index-Spalten nutze ich für einen sog. Self-Join. Dabei joine ich ein und dieselbe Tabelle mit sich selbst (daher „Self“-Join). Die Schlüsselkriterien für den Join sind jeweils die beiden Index-Spalten:
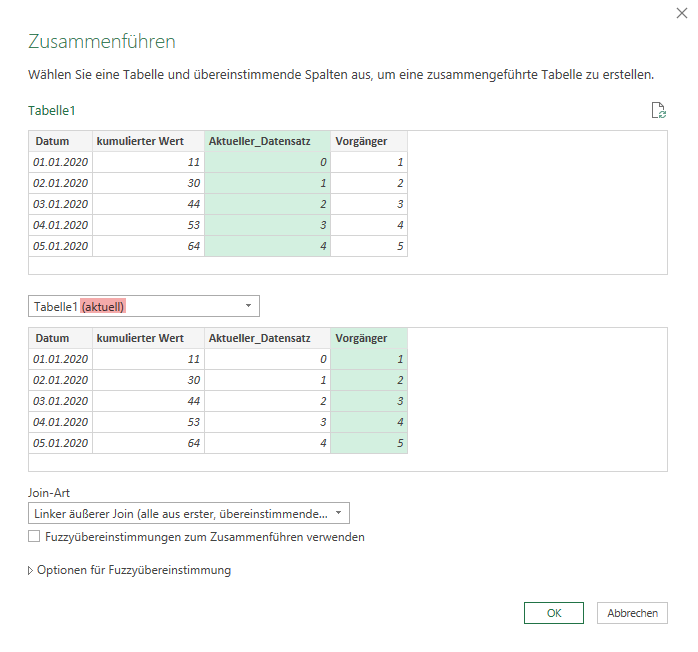
Als Ergebnis des Self-Joins über die Index-Spalten ergibt sich je Datensatz eine Tabelle mit genau einem Datensatz: Nämlich dem Datensatz des Vortages:
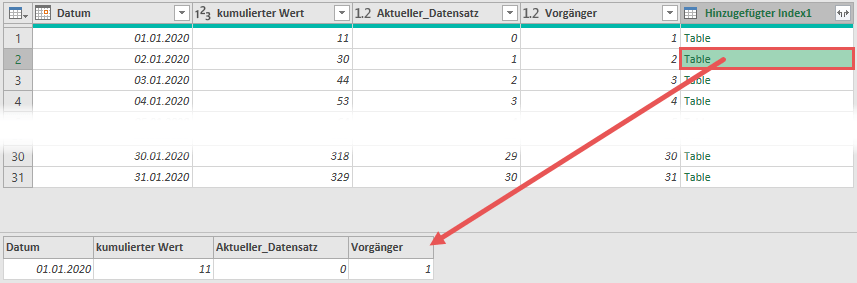
Wenn ich nun aus dieser bestehenden Ergebnistabelle die Spalte kumulierter Wert expandiere, dann habe ich sowohl den kumulierten Wert bis zum aktuellen Tag, als auch den kumulierten Wert bis zum Vortag in einem Datensatz, d. h. in einer Zeile:
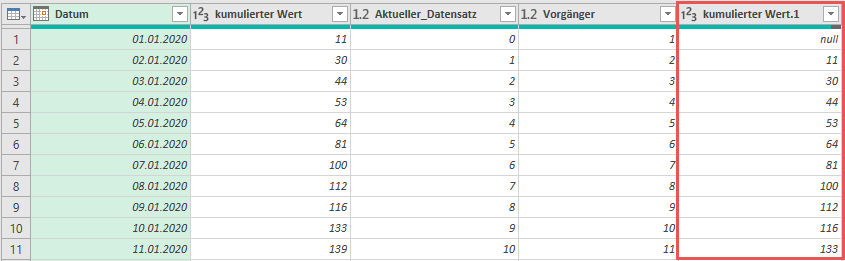
Damit bin ich relativ einfach in der Lage, die Differenz zu kalkulieren und somit an den Einzelwert je Tag heranzukommen.
Kalkulation der Differenz aus aktuellem Tag und Vortag
Das Wesentliche Problem – nämlich die aktuellen Werte mit den Werten des Vortages vergleichen zu können – ist bereits geschafft. Kommt noch die Kalkulation der Differenzen, um auf die Tageseinzelwerte zu kommen. Das einzige was hier zu beachten ist, ist der null-Wert in der ersten Zeile. Dieser beruht darauf, dass es für den 01.01.2020 keinen Vortageswert gibt und der Join somit eine leere Menge (genannt null, nicht Null!) zurückliefert. An dieser Stelle musst Du wissen, dass Du nicht einfach 11 minus null rechnen kannst, weil dies ebenfalls null ergibt. Ich löse diese Problemstellung auf die folgende Weise:
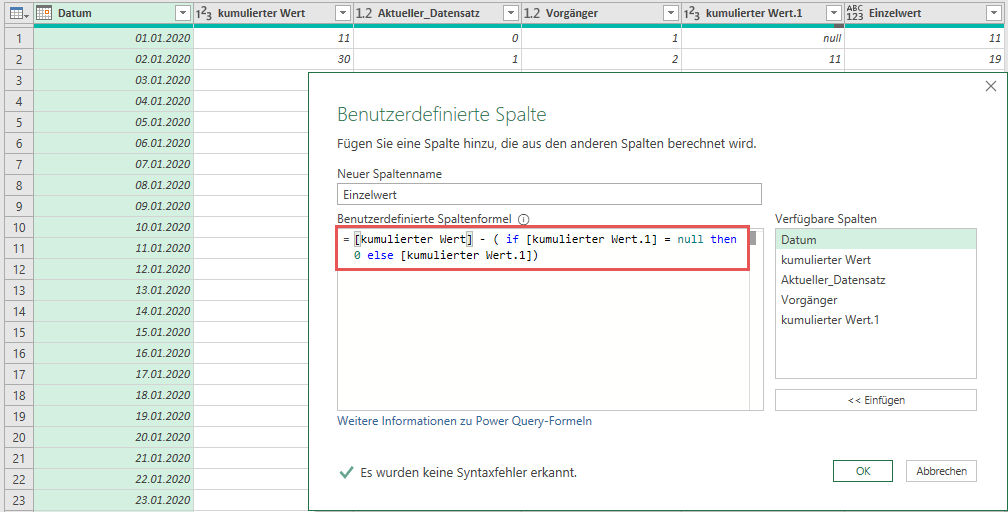
Als letzten Schritt gilt es die nun nicht mehr benötigten Spalten zu entfernen. Das finale Ergebnis sieht dann bei mir so aus:
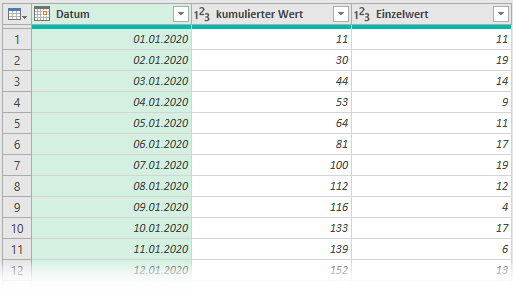
Diese Art des Vorgehens kann ich in Power Query an vielen Stellen nutzen. Ich hoffe, es eröffnet Dir die Sicht auf viele weitere Problemlösungen 🙂
Bis zum nächsten Mal und denk dran: Sharing is caring. Wenn Dir der Beitrag gefallen hat, dann teile ihn gerne. Falls Du Anmerkungen hast, schreibe gerne einen Kommentar, oder schicke mir eine Mail an lars@ssbi-blog.de
Viele Grüße aus Hamburg,
Lars

Lars ist Berater, Entwickler und Trainer für Microsoft Power BI. Er ist zertifizierter Power BI-Experte und Microsoft Trainer. Für sein Engagement in der internationalen Community wurde Lars seit 2017 jährlich durch Microsoft der MVP-Award verliehen. Lies hier mehr…

Torsten meint
Hi Lars,
danke für den Beitrag, ist genau, was ich suche/brauche (Ermittlung von Verbräuchen aufgrund von täglich erfassten Zählerständen).
Kannst Du mir an dem einen Punkt noch einen Tipp geben, da komme ich nicht weiter (bis dahin hat alles einwandfrei geklappt):
Wenn ich nun aus dieser bestehenden Ergebnistabelle die Spalte kumulierter Wert expandiere, dann habe ich sowohl den kumulierten Wert bis zum aktuellen Tag, als auch den kumulierten Wert bis zum Vortag in einem Datensatz, d. h. in einer Zeile
Hier weiß ich nicht, wie man „aus der bestehenden Ergebnistabelle die Spalte kumulierter Wert expandiert“. Kannst Du mir sagen, wie das gemacht wird?
Vielen Dank und viele Grüße
Torsten
Lars Schreiber meint
Hallo Torsten,
ich muss zu meiner Schande gestehen, dass ich das wirklich nicht beschrieben habe, weil ich dieses Wissen einfach vorausgesetzt habe. Das ist von mir natürlich nicht okay 😉 Also: Die Spalte mit den Tabellen-Objekten expandierst Du, indem Du in der Überschrift der Spalte rechts auf diesen Doppelpfeil klickst, bei dem der linke nach links und der rechte nach rechts zeigt. Danach kannst Du wählen, welche Spalten der Tabelle zu expandieren möchtest. Ich hoffe, das hat geholfen 🙂
Viele Grüße,
Lars
Marc meint
Sehr schön! Ich werte Logdateien eines Wechselrichters aus, dessen Zähler den Ertrag, die Erzeugung und die Netzeinspeisung kummuliert speichert. Mich interessieren jedoch auch die Veränderung/ Tag -> und da ist der vorgestellte Ansatz genau richtig.
Bisher habe ich die Auswertungen „manuell“ in Excel durchgeführt. Die Möglichkeiten von PowerQuery werden mir erst zunehmend bewusst. Die vollkommen andere Vorgehensweise ist mir jedoch noch vielfach ungewohnt, so dass ich über Blogbeiträge wie diesen sehr erfreut bin!
Weiter so!
Marc
Alex Wenzel meint
Hi Lars,
vielen Dank für deinen Beitrag.
Mir kam beim Lesen die Idee eines etwas anderen Weges. Da ich noch nicht lange in der PBI-Welt lebe kann es gut sein, dass ich etwas übersehe, daher wollte ich gerne deine Meinung dazu hören.
Ich habe genau deine, nach Datum sortierte, Tabelle genommen und folgenden Code ergänzt:
#“Hinzugefügter Index“ = Table.AddIndexColumn(#“Geänderter Typ“, „Index“, 0, 1),
#“Hinzugefügte bedingte Spalte“ =Table.AddColumn(#“Hinzugefügter Index“,“Einzelwert“,
each if
[Index] = 0 then [kumulierter Wert]
else
[kumulierter Wert]-#“Hinzugefügter Index“{[Index]-1}[kumulierter Wert])
Letztlich subtrahiere ich jeweils von meinen kumulierten Wert den jeweiligen Wert aus Index-1
Damit spart man sich die ganzen Spalten und vor allem den Join.
Ich bin gespannt auf deine Meinung.
Danke und viele Grüße
Alex
Lars Schreiber meint
Hallo Alex,
danke für Deinen Kommentar und Dein Feedback. Ja, Deine Lösung liefert das korrekte Ergebnis und kann auf Basis eines einzigen Jahres sicherlich auch genutzt werden (was bei YTD-Kalkulationen ja gegeben ist). Sofern man dieses Vorgehen jedoch mit einer größeren Anzahl an Datensätzen nutzt (ich habe das mal mit einem Life-to-Date über viele Jahre getestet), ist der Join einfach rasend schnell und Dein Ansatz extrem langsam. Also ja, für den von mir gezeigten Fall, kannst Du sicherlich auch Deine Lösung nutzen. Für größere Datenmengen, oder auch andere Vergleiche, ist die Join-Variante vermutlich der bessere Ansatz.
Danke und viele Grüße,
Lars
Alex Wenzel meint
Hallo Lars,
dachte mir ja schon, dass das bestimmt irgendwo ein Haken hat.
Habe es jetzt interessehalber auch simuliert mit 10k Datensätzen. Ich verstehe zwar nicht was da datenverarbeitungs-seitig so unterschiedliches passiert aber der Join war tatsächlich an die 1000x so schnell.
Einfach Wahnsinn!
Damit werde ich meine „Abkürzungen“ künftig deutlich kritischer hinterfragen!
Vielen Dank dir (auch für dein tollen Blog!)
VG
Alex
Lars Schreiber meint
Hi Alex,
solange Deine „Abkürzungen“ in Deinen Szenarien brauchbare Ergebnisse liefern, ist ein „Hinterfragen“ nicht nötig. Erst wenn die Ergebnisse falsch sind, oder die Performance Deiner Lösung inakzeptabel lang, dann muss man sich ans Optimieren machen. Insofern: Alles gut 🙂
Danke für Dein Feedback und hab ein schönes Wochenende,
Lars
Ana Maria Bisbe York meint
Hi Lars,
Thanks for the solution. It’s very creative and simple.
I do not speak German and even for me was really easy to follow and to reproduce the solution. Thanks again !! Vielen Dank 🙂
Regards, Ana
Tobias meint
Hey Lars,
vielen Dank für diesen Post – das ist DIE Lösung!
Ich habe zwar keine kumulierten Werte, aber dafür Stempeluhr-Zeiten, bei der ich ebenfalls mit der „Zeile darüber“ verrechnen muss. Das sollte mit diesem Lösungsansatz ja auch gehen. Probiere ich gleich aus 🙂
Lars Schreiber meint
Hallo Tobias,
freut mich sehr, dass der Beitrag nützlich für Dich war 🙂 Danke für Dein Feedback und ich hoffe, es hat Dir zur Lösung verholfen 🙂
Viele Grüße aus Hamburg,
Lars