The M language has so-called structured values, to which lists, records and tables belong. Each value type serves specific purposes and this post is intended to give an introduction to tables. This post is part of a series about lists, records and tables in M.
What is a table in M?
In M there are two kinds of values: primitive and structured values. Examples for primitive values are:
- „a“,
- 1,
- true.
They are primitive in that way, that they are not contructed out of other values. In contrast to primitive values, we have so called structured values in M, which are composed of other values, primitive and structured ones. A table is one of those structured values (the others are lists and records) and it is described as „a set of values organized into columns (which are identified by name), and rows.“
Even if tables usually contain columns and rows, they can be empty, which looks like this: #table({},{}).
An example of a very simple representative of a table is:
#table( {"column_1", "column_2"}, { {1, 2}, {3, 4} } )
Before taking a more detailed look at tables of what they are and what they are for, let’s discuss why to use tables at all.
Why use table at all?
Tables are often the final result of a query, which can then either be used as an intermediate query or loaded into the data model in Power BI and Power Pivot. In addition, there are functions that work with tables as input parameters and others that generate tables as return values. For these reasons it is necessary to know how to deal with them in order to use the M language safely.
How to create tables in M with native M functions
There is no literal syntax to create a table, like for records ([]) and lists ({}), but there are several native M functions, that create tables.
#table()
This function (it is spoken „pound table“) is something special, as it is not (yet) returned by the intrinsic variable #shared. Since the first parameter of the function can be used in different ways, there are several ways to use this function.
The second parameter is always a list of list, filled with values. Each inner list represents a row within the table. Let’s take a look how the first parameter can be used in different ways.
Version #1 – Specifying column names in a list
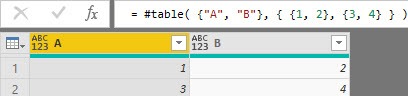
#table( {"A", "B"}, { {1, 2}, {3, 4} } ) →By specifying the column names as text values in a list, every column gets its specific column name.
Version #2 – Defining a number of columns
#table(5, {{ 1,2,3,4,5}} ) → If I need to create a known number of columns (e.g. 100), but they only need to have values and no specific column headings, I can use this syntax.

Version #3 – Using so called ascribed types to define column names and types
#table( type table [A = number, B = text], {{1,"one"}, {2,"two"}, {3,"three"}} ) → With this version you can define not only the column headings and the corresponding values, but also the data types of the individual columns.

I will describe why using ascribed types for defining types of values in a column of a table is a BAD IDEA later in a separat section of this post. Now let’s take a look at functions that create tables from other values in M.
Conversion functions: Table.From*()/ *.ToTable
Conversion functions create a table from other values, like lists, records etc. Here a few prominent representatives:
Other M functions that return tables
In addition to the conversion functions, there is a ton of other functions returning tables in M. First of all I want to mention those functions that allow you to define tables yourself by giving them lists built in either row or column logic:
In addition to these functions, there are many more that return tables. Most of them are connectors to external data sources. Examples of this are: Csv.Document(), DataLake.Files(), or Github.Tables().
Don’t use ascribed types for type definitions
Dealing with types in M is really tiresome. In several places I stumbled across problems in M whose solution was to be found in M’s type system. I had written under Version #3 that it is not recommended to ascribe types to the values of a column in a table. I wrote a blog post about it, which describes the reasons in detail and I recommend you read it, before going further in this post. In short Power Query accepts your type definition via ascribed types as correct and does no validation, wether the declared type of the column is compatible with the values in that column. Only when you try to load these values into another engines (Excel data model, the Power BI data model, or pure Excel) will you get error messages because these systems recognize the error.
Operators for tables + equivalent functions
There are 3 operators that can be used in conjunction with tables: „=“ and „<>“ make it possible to compare tables, while „&“ combines tables. Here are some examples of how to use that:
#table({"A","B"},{{1,2}}) = #table({"B","A"},{{2,1}}) → true. Tables are equal if all of the following are true:
- The number of columns is the same.
- Each column name in one tables is also present in the other table (regardless of its position in the table).
- The number of rows is the same.
- Each row has equal values in corresponding cells.
#table({"A","B"},{{1,2}}) = #table({"B","A"},{{2,1}, {3,4}}) → false, due to a different number of rows.
#table({"A","B"},{{1,2}}) <> #table({"B","A"},{{2,1}, {3,4}}) → true
#table({"A","B"}, {{1,2}}) & #table({"B","C"}, {{3,4}}) → #table({"A","B", "C"}, {{1,2, null}, {null, 3,4}}). This can also be achieved using the function Table.Combine({ #table({"A","B"}, {{1,2}}), #table({"B","C"}, {{3,4}}) }).
Accessing table elements
Once you have a table, it is often necessary to access specific items within the table directly.
Accessing a single column
TableName[ColumnName] → the result is a list. Therefore Value.Is(#table({"A","B"},{{1,2}})[A], type list) returns true. If you want to learn more about lists, read this post.
Accessing a single row
TableName{zero-based row index} → the result is a record. Therefore Value.Is(#table({"A","B"},{{1,2}, {3,4}}){1}, type record) returns true. If you want to learn more about records, read this post.
Accessing a single cell
Accessing a cell in a table brings accessing a row and accessing a column together:
TableName[ColumnName]{zero-based row index} which is equivalent to TableName{zero-based row index}[ColumnName], column and line references can therefore be swapped.
The result has no predictable type because it returns what is in the cell and that can be anything: a scalar value, a list, a record, another table, a function, etc.
Special functions to select elements in a table
If you don’t want to address only one column, one row, or a certain cell of a table, but need to select several columns or rows by condition, there are functions in M that help you. Here are a few examples:
Table.SelectRows() → Returns a table of rows from the table, that matches the selection condition.
Table.SelectColumns() → Returns a table with only specific columns that match the selection conditions. The third and optional parameter missingField of this function is very useful, which says what to do if the addressed field (column) does not exist.
- MissingField.Error → Default: Return an error
- MissingField.Ignore → Don’t select the column
- MissingField.UseNull → Fill the column with null values
Table.ColumnsOfType() → This function is very useful, if you want to select columns of your table, which match a specified type or a list of types. That way you can for example select all columns that are of type text. Although this function can be very helpful, it does not always return the expected columns. I’ve written a post about this that deals with pitfalls with Table.ColumnsOfType.
Other special table functions
If you want to get meta information about the table you are using, the following two functions will help you:
Table.Schema() → This function returns information about the columns of the table, like:
- the 0-based position of the column in table,
- the name of the type of the column,
- nullability,
- maximal length,
- …
Table.Profile() → Returns the following information for the columns in a table:
- minimum,
- maximum
- average
- standard deviation,
- count
- null count
- distinct count.
Table.Buffer() → This is a special function, which is used, among other things, when it comes to query performance optimization, as it keeps a snapshot of the table in memory. There are several good blog posts out there, that cover this topic. See Imkes post about Table.Buffer inside List.Generate to improve performance.
Even though there is much more to say about tables and their capabilities, I hope this was a helpful introduction to the topic 🙂
Greetings from Germany,
Lars

Lars ist Berater, Entwickler und Trainer für Microsoft Power BI. Er ist zertifizierter Power BI-Experte und Microsoft Trainer. Für sein Engagement in der internationalen Community wurde Lars seit 2017 jährlich durch Microsoft der MVP-Award verliehen. Lies hier mehr…