Nervt es Dich auch, dass Anfügetabellen in Power Query häufig Spalten enthalten, die für Dich überhaupt nicht interessant sind? Klar kannst Du diese manuell entfernen und sie tauchen dann auch nie wieder auf. Aber was, wenn in der Anfügetabelle beim nächsten Mal eine neue Spalte existiert, die Du wieder nicht haben möchtest? Ich bin in meinem letzten Beitrag Unterschiedliche Datenstrukturen mittels Power Query anfügen auf die Sinnhaftigkeit von Strukturtabellen eingegangen. Im heutigen Beitrag werde ich Dir zeigen, wie man Anfügetabellen mit Power Query automatisch an die Strukturtabelle anpassen kann. Damit sorgst Du dafür, dass aus allen Anfügetabellen automatisch nur diejenigen Spalten akzeptiert werden, die in der Strukturtabelle vorhanden sind.
Als Abonnent meines Newsletters erhältst Du die Beispieldateien zu den Beiträgen dazu. Hier geht’s zum Abonnement des Newsletters!
Die Problemstellung: Aufbau von Strukturtabelle und Anfügetabellen weichen voneinander ab
Aus meiner täglichen Arbeit kenne ich es, dass Daten von verschiedenen Personen zugeliefert werden, um dann zu einer einheitlichen Datenbasis aufbereitet zu werden. Hierfür definiert man zuvor mit diesen Personen ein einheitliches Format für die Daten und erwartet bei Zulieferung der Daten eben dieses Format vorzufinden. Das klappt in der Realität leider nicht immer. Daher wäre es sinnvoll all jene Spalten der zugelieferten Daten dynamisch zu entfernen, die in der Strukturtabelle nicht vorkommen. Die Strukturtabelle definiert dann also nicht mehr nur die Reihenfolge der enthaltenen Spalten, sondern bestimmt gleichzeitig die erlaubten Spalten aller Anfügetabellen.
Nehmen wir das folgende Szenario: Die Strukturtabelle (linke Abbildung) definiert, dass die finale Tabelle die Spalten A, B, C und D in exakt dieser Reihenfolge haben soll. Die finale Tabelle (rechte Abbildung), die aus den Anfügungen aller anderen Tabellen entsteht, weist die Spalten A, B, C und D in eben dieser Reihenfolge aus. Zusätzlich existiert jedoch auch Spalte E, die in einer der Datenzulieferungen vorhanden war, für mich aber vollkommen uninteressant ist.

Schauen wir uns hierzu einmal an, was passiert, wenn ich über die Nutzeroberfläche (GUI) in Power Query manuell eine Spalte entfernen.
Die ungeliebte Lösung: Ungewünschte Spalten manuell entfernen
Um die ungewünschte Spalte E zu entfernen, kann ich mit der rechten Maustaste auf den Spaltenkopf der Spalte E klicken und entfernen auswählen (linke Abbildung).

Daraufhin wird die Funktion Table.RemoveColumns() eingefügt, die in ihrem zweiten Parameter {„E“} definiert, dass die Spalte E immer entfernt werden soll. Diese Lösung hat jedoch zwei gravierende Nachteile, auf die ich hier kurz eingehen möchte.
Was ist, wenn die Spalte E mal nicht mehr mitgeliefert wird?
Wenn aus einem unerfindlichen Grund die Spalte E, so unerwünscht sie für unsere finale Tabelle auch sein mag, auf einmal nicht mehr mitgeliefert wird, dann greift meine eingebaute Entfernung der Spalte E ins Leere. Dies führt zu folgender Fehlermeldung:
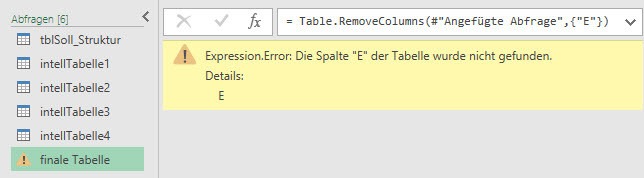
In meiner Abfrage hatte ich fest verankert, dass die Spalte E immer entfernt werden soll. Kommt diese Spalte aber auf einmal nicht mehr vor, so sucht mein Skript dennoch nach Spalte E um diese zu entfernen. Da es diese Spalte nicht finden kann, erhalte ich diese Fehlermeldung. Es gibt über den dritten Parameter dieser Funktion eine Möglichkeit, dieses Probmem zu heilen. Dies soll hier jetzt jedoch nicht Thema sein. Mit unserer entgültigen Lösung, werden wir dieser Problematik auf einem anderen Wege beikommen.
Was ist, wenn eine neue ungewünschte Spalte hinzukommt?
Nehmen wir nun den Fall, dass Spalte E auch weiterhin vorhanden sein wird, aber durchaus auch andere Spalten von Zeit zu Zeit hinzukommen. Beispielsweise könnte es ja sein, dass die Datenzulieferungen die Spalte X und Z enthalten. Wenn ich definieren möchte, welche Spalten alle nicht in der finalen Tabelle zugelassen sind, führt dies zu einem unendlichen Spiel. Drehen wir den Spieß an dieser Stelle doch einmal um: Ich definiere jetzt nicht, welche Spalten entfernt werden sollen, sondern welche Spalten bestehen bleiben sollen.
So definiert Du, welche Spalten bestehen bleiben sollen
Anstatt in der finalen Tabelle zu definieren, welche Spalten stets zu entfernen sind, ist es deutlich sinnhafter diejenigen Spalten zu definierren, die bestehen bleiben sollen. Hierzu markiere ich die gewünschten Spalten A, B, C und D und führe mit der Maus einen Rechtsklick in einer der markierten Spalten aus. Anschließend wähle ich Andere Spalten entfernen aus dem Menü aus (linke Abbildung).

Als Ergebnis erahlte ich die Funktion Table.SelectColumns(), die über ihr zweites Argument {„A“, „B“, „C“, „D“} die gültigen Spalten definiert. An dieser Stelle habe ich schon mal eine ganze Menge erreicht:
- Ich habe nun definiert, dass nur die Spalten A, B, C und D als gültige Spalten bestehen bleiben dürfen
- Alle Spalten, die nicht die Bezeichnung A, B, C, oder D haben, werden nun automatisch aus der finalen Tabelle entfernt.
Das ist schon mal sehr dynamisch. Fehlt aus meiner Sicht nur noch eines: Ich hatte die Strukturtabelle ursprünglich dafür erstellt, um die Reihenfolge der Spalte meiner finalen Tabelle zu definieren. Schön wäre es doch jetzt, wenn hierüber nicht nur die Reihenfolge der Spalten definiert würde, sondern auch gleich die erlaubten Spalten mitgegeben würde. In meinem Beispiel hieße das, dass durch die in der Strukturtabelle enthaltenen Spalten A, B, C und D auch gleich festgelegt ist, dass in der finalen Tabelle nur diese vier Spalten erlaubt sind. Sofern wir die Strukturtabelle jedoch um eine Spalte X erweitern, wäre auch automatisch diese Spalte X in der finalen Tabelle erlaubt. Schauen wir uns das einmal im Detail an.
Die anpassungfähige Lösung: So passen sich die Anfügetabellen automatisch der Strukturtabelle an
Ich hatte im vorherigen Beispiel durch die Nutzung der Power Query GUI bereits auf die Funktion Table.SelectColumns zugegriffen. Diese sieht im Detail wie folgt aus:
Table.SelectColumns(table as table, columns as any, optinal missingFiled as nullable number)
Hier kurz zu den Parametern der Funktion:
- table: Die Funktion setzt auf einer bestehenden Tabelle (zumeist dem letzte Schritt in der aktuellen Abfrage) auf und selektiert von dieser definierte Spalten
- columns: Hier werden die Spalten definiert, die weiterhin bestehen bleiben sollen. Dass dieses Argument vom Typ any ist, ist super, denn damit werden wir gleich arbeiten
- missingField: Dies ist ein optionaler Parameter. Er muss also nicht gesetzt werden. Er definiert, wie damit umgegangen werden soll, falls die entsprechende Spalte nicht vorhanden ist.
Der Hilfetext zu dieser Funktion lautet: Diese Funktion gibt eine Tabelle zurück, die nur die angegebenen Spalten beinhaltet. Da das zweite Argument columns vom Typ any ist, heißt dies, dass wir hier auch eine Liste von Spalten übergeben können. Diese Liste hatten wir im vorherigen Beispiel fix mit {„A“, „B“, „C“, „D“} definiert. Bevor ich dies dynamisieren kann, muss ich mir die Frage stellen, welche Liste von Spalten hier eigentlich interessant wäre? Die Antwort lautet: Die Spaltenbezeichnungen unserer Strukturtabelle!
Mit dynamischen Listen zur flexiblen Sollstruktur
Um eine dynamische Liste von Spaltenüberschriften der Strukturtabelle (die sich mit verändert, wenn sich der Aufbau meiner Strukturtabelle verändert) zu erzeugen, erstelle ich mit einem Rechtsklick auf die Abfrage zunächst einen Verweis auf die Strukturtabelle.
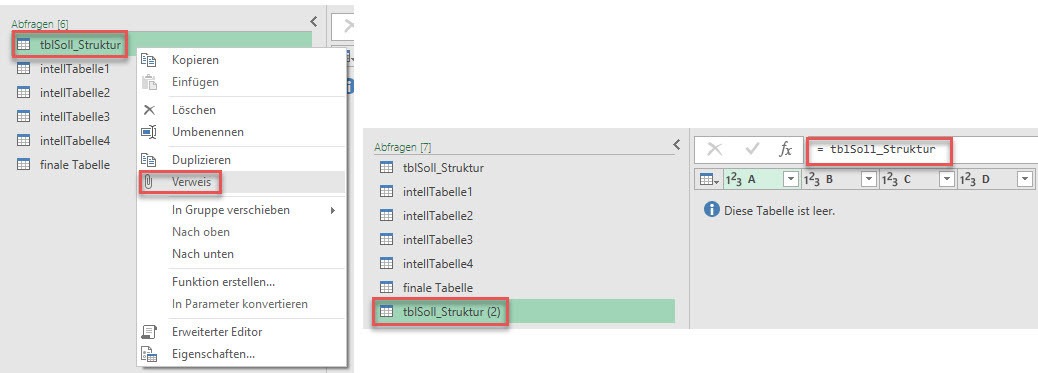
Nachdem ich den Verweis erstellt habe, lautet die Formel in der neuen Abfrage = tblSoll_Struktur (rechte Abbildung).
Dies hat zur Folge, dass jede Änderung, die ich in der Strukturtabelle vornehme auch automatisch die Struktur der neu erstellten Tabelle beeinflusst. Da ich eine Liste mit den Spaltenbeschriftungen haben möchte, nutze ich die Funktion Table.ColumnNames(), so dass das Ergebnis wie folgt aussieht:
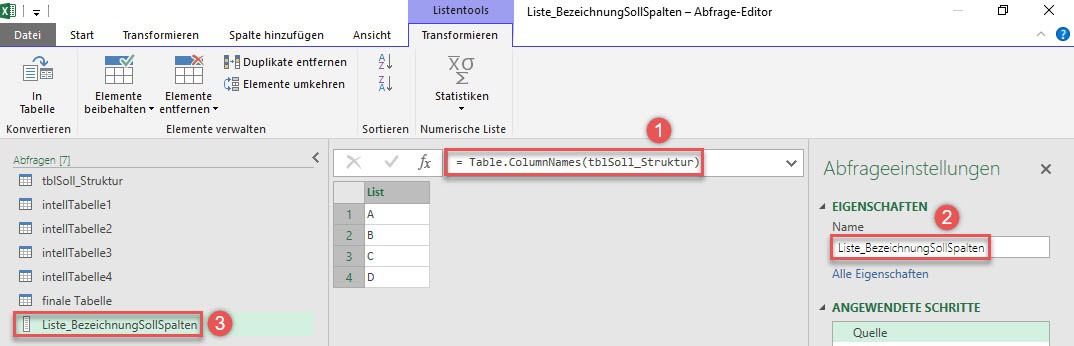
Ich benenne diese Abfrage sogleich um in Liste_BezeichnungSollSpalten (Schritt 2), was zur Umbenennung in Schritt 3 führt. Was habe ich jetzt erreicht? Jetzt habe ich eine Liste mit Spaltenbezeichnungen der Strukturtabelle, die sich automatisch an Veränderungen in der Strukturtabelle anpasst.
Diese dynamische Liste kann ich nun in der finalen Tabelle wie folgt nutzen.
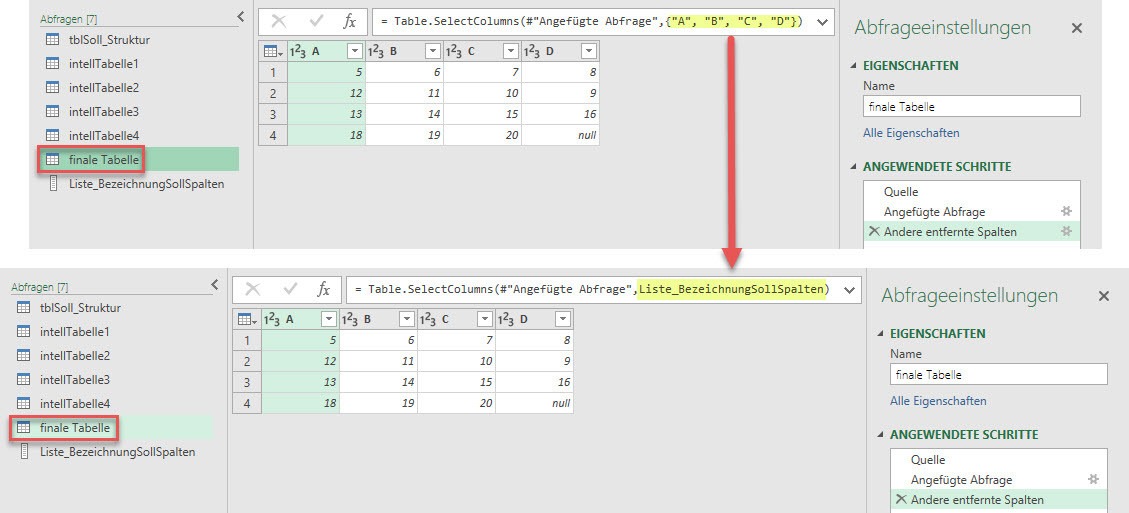
Geschafft, von nun an ist es egal welchen Aufbau die Strukturtabelle hat: Ausschließlich die in ihr enthaltenen Spalten werden auch von den Anfügetabellen übernommen. Ändere ich also das Layout der Strukturtabelle derart, dass auch eine Spalte E enthalten ist (linke Abbildung), wirkt sich dies auf die Struktur der finalen Tabelle aus (rechte Abbildung).

Und nun wünsche ich Dir viel Spaß beim Experimentieren mit den Anfügeprozessen in Power Query.
Bis zum nächsten Mal und denk dran: Sharing is caring. Wenn Dir der Beitrag gefallen hat, dann teile ihn gerne 🙂
Viele Grüße aus Hamburg,
Lars

Lars ist Berater, Entwickler und Trainer für Microsoft Power BI. Er ist zertifizierter Power BI-Experte und Microsoft Trainer. Für sein Engagement in der internationalen Community wurde Lars seit 2017 jährlich durch Microsoft der MVP-Award verliehen. Lies hier mehr…
