In our last post Imke and I discussed the environment concept in M on the basis of the native M function Expression.Evaluate(). This current post will cover custom M functions and the importance of the environment concept for those functions. Let’s go…
You can download all code samples from here. If you already have my Power Query editor for Notepad++ (or want to build it) you can open the file in Notepad++. Otherwise open it in a simple text editor and paste it into the Advanced Editor of Power Query or Power BI Desktop.
Environments in custom M functions
Writing custom functions in M can be key to solving more advanced problems in Power Query. More often than you might think, good knowledge of the environment of the function is crucial for overcoming error messages and getting correct results. Let’s work with an example.
Creating a Running Total
Calculating a running total is not an easy task in Power Query and therefore it is a very good example for writing custom M code. There are easier and way faster methods to calculate a running total than the one we have chosen here, but the following code examples serve a diadactic approach. We will develop the solution together. In the end you will see how it works and what environments have to do with the solution.
The idea
The idea of a running total is pretty simple. Take a look at the following screenshot:
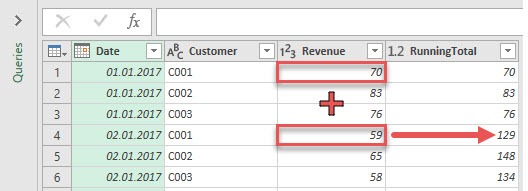
The table shows revenue by customer and date. The running total calculates the revenue by customer for the current date and all previous dates. Let’s see how this approach can be implemented.
1. Attempt – stuck in row reference
The first attempt is for didactic reasons only. We add a new column and create a sum over the revenue column, by using List.Sum([Revenue]).
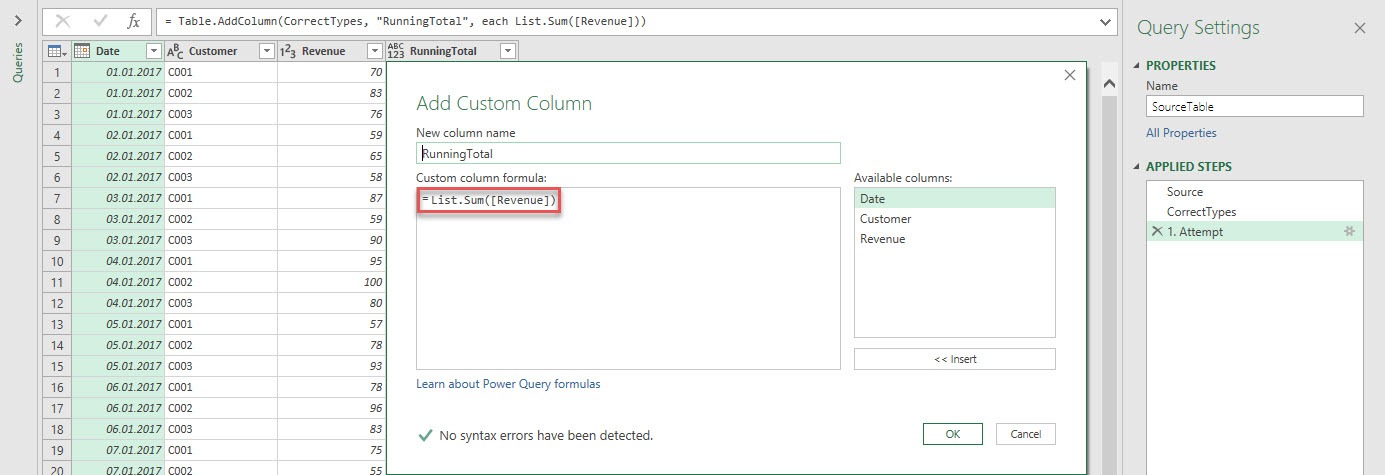
You might be surprised, that you don’t even get a result, because the following error message appears:
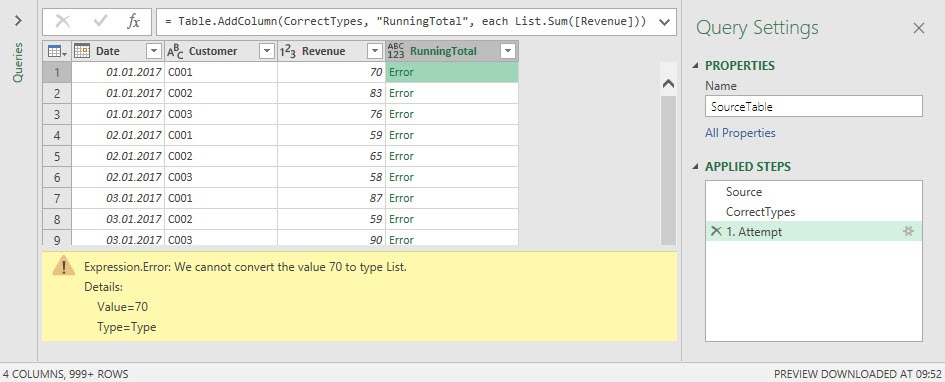
List.Sum() expects a list, but calculating this formula inside a Table.AddColumn function (what automatically happens, when you push the Custom Column button in the UI) creates a calculation by row. Because the formula List.Sum() is calculated row wise, this leads to only one single value (not a list) per calculation. This is what the error message tells us: It gets the value 70 (in row one) but expects a list instead! Let’s try another attempt.
2. Attempt – the overall sum
To overcome the issue from attempt 1, we now do not refer to the revenue of the current table, but to the revenue of the table in our second step: CorrectTypes! The List.Sum() function (which is inside the Table.AddColumn() function, that you can only see in the formula bar and the advanced editor) looks as follows:
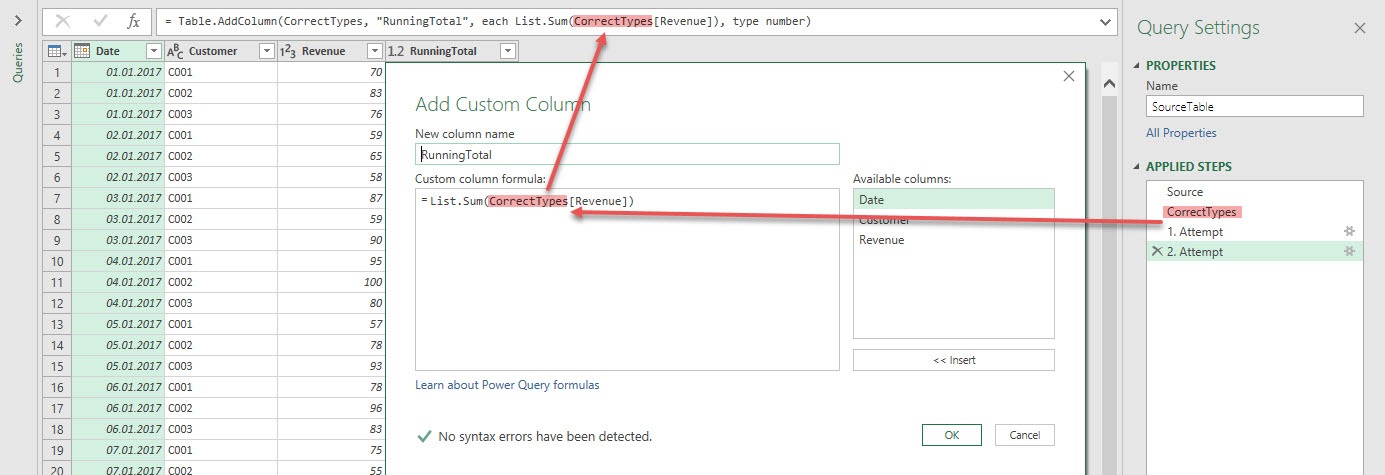
Let’s take a look at the result.

Okay, we don’t have an error message any more. But the result doesn’t look very promising, because we get the same number in each row of the newly calculated column. This number is the sum over the complete revenue column, which is not our desired result. What we need to calculate is a sum over a subset of rows of the source table, which is different for each row in the newly calculated column. Let’s do that!
3a Attempt – aggregating over subsets of the source table
The last attempt got us closer to the desired result, but we are not looking for the value 82.145 in each row of the newly calculated column. We are looking for the sum over only a subset of rows of the source table. Calculating a sum over a subset of a table, brings us to the function Table.SelectRows(). What we want to calculate is the following:
- for each row of the source table
- create the sum over
- a subset of the source table (in our example table CorrectTypes) where
- the customer in the current row (of the current table) is equal to the customer in the source table and the date in the source table is smaller than or equal to the date in the current row (of the current table).
So we have to iterate the source table twice. For each row in the source table we calculate a sum over a subset of the same table! Translated into code it could look like this:
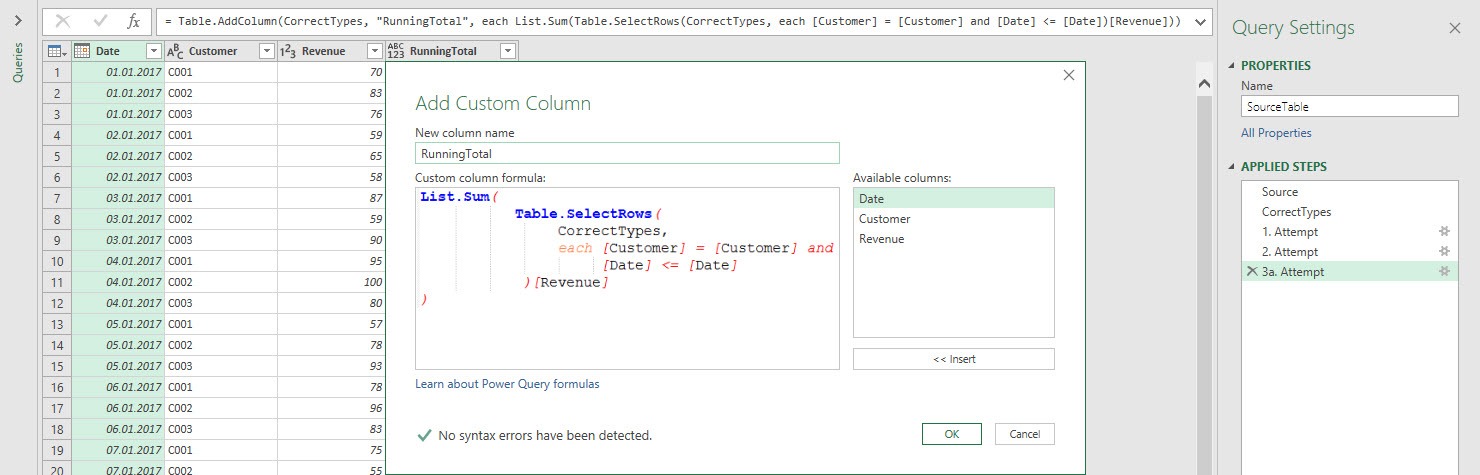
Take a look at the result.
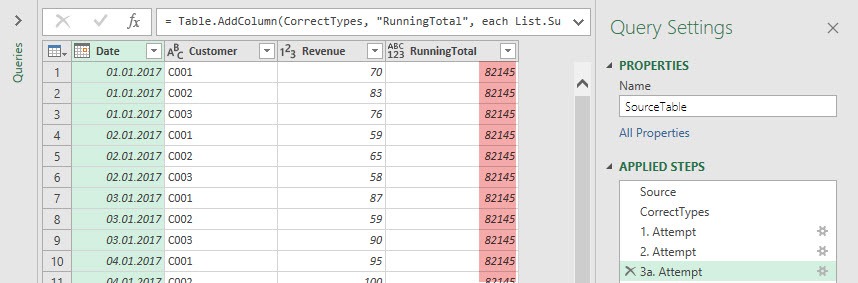
Again we get 82.145 as a result for each row, but why? To find the answer let’s take a look at the complete formular of this step (copied from the advanced editor):
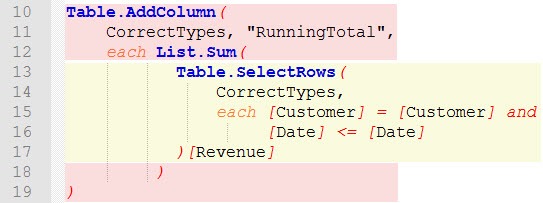
We have two main parts here, the red part and the yellow part. Let’s spend some more time here:
- red part: Adds a new column to the table CorrectTypes and creates a sum for each row in CorrectTypes. That’s the first iteration over the source table CorrectTypes.
- yellow part: The sum, which is created in the red part, is built on a subset of rows of the same table CorrectTypes. This subset is built by using the Table.SelectRows() function, which checks row by row, if the specific row should be included in the sum or not. This is the second iteration over the source table.
The problem with this code is, that to get correct results, the inner iteration (yellow part) needs to access variables from the outer iteration (red part). What we want to obtain is the following:
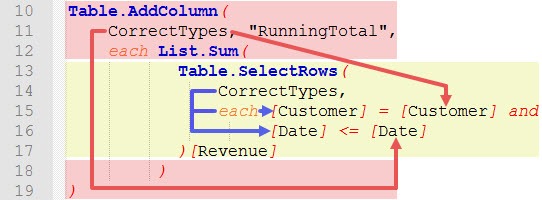
Within the Table.SelectRows() function we want to compare Customer and Date from the inner iteration (blue arrows) of the source table (table CorrectTypes) with Customer and Date from the outer iteration (red arrows).
Unfortunately this is not what the code does! The code does the following:
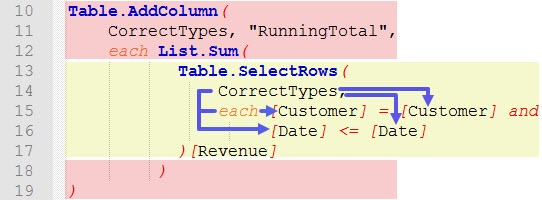
The code only compares Customers and Dates from within the Table.SelectRows() function, which is the inner iteration. Because [Customer] = [Customer] and [Date] <= [Date] is true for each row within the inner iteration, the result always is 82.145.
But how can we reach the outer iteration for comparison? Let’s see the final solution and its explanation.
3b Final Attempt
The following solution is the one that works properly. Please take a special look at the green marked Qs, which we will explain later.
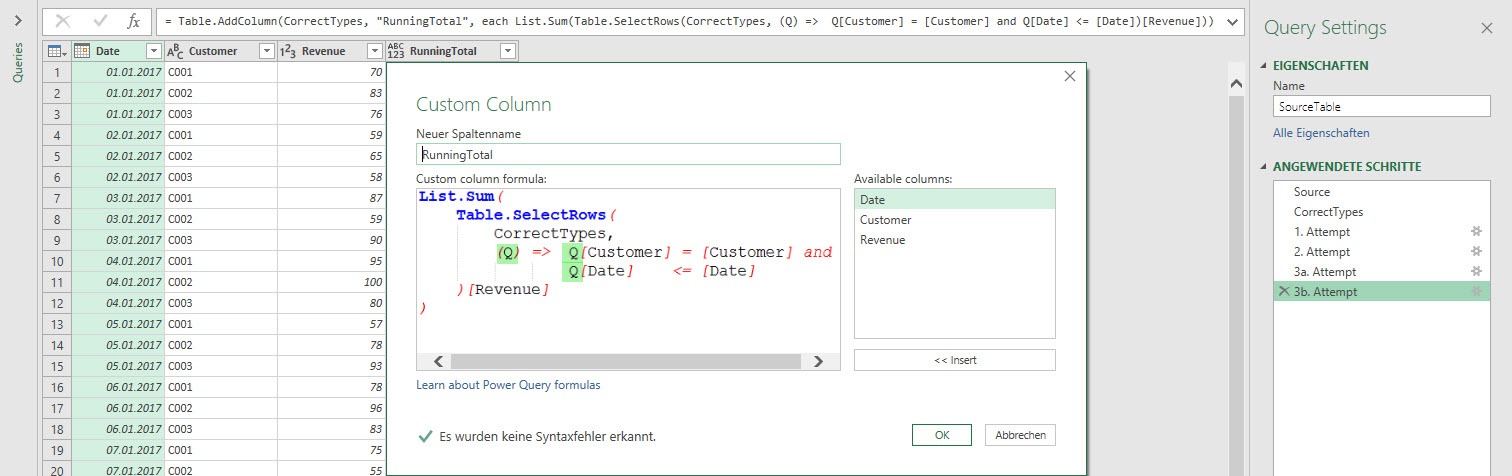
The result is the desired running total calculation.
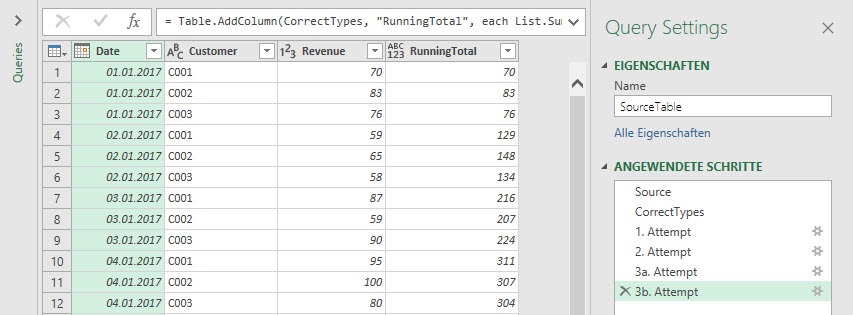
Okay, we’ve finally got the right calculation, but what does this strange looking Q stuff mean?
The reason why 3b Attempt solves our problems
This kind of solution has been the reason, why I (Lars) started investigating in the Power Query Formula Language Specification, because I didn’t understand, why this strange syntax worked. This led me to the Environment topic. Imke and I thought, that it is likely, that there are more people out there, having difficulties with this syntax as well.
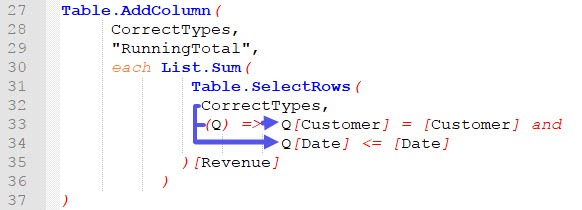
Take a look at the following screenshot, which shows the function from the advanced editor. For now, the only important thing to notice is, that we replaced the second each by (Q)=>.
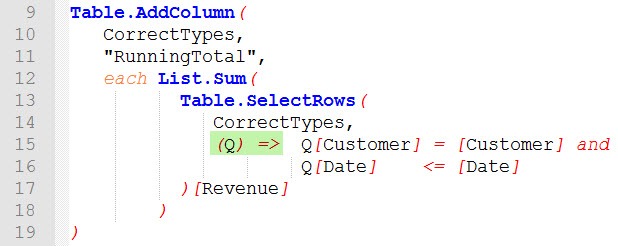
Each is a keyword to create simple functions. Each is an abbreviation for (_) =>, in which the underscore represents (if you are in a table environment, as we are) the current row. We’re doing the following:
- We replace the underscore bei Q. Q could have been anything else (e. g. Inner).
- We add Q as a prefix to the fields we want to bind to the inner table CurrectTypes (Q[Customer], Q[Date])
The reason, why we use a parameter (Q) inside the function initialization syntax is the following:
- Everytime, when the function is invoked (which means, that the function is evaluated and delivers a value) the environment, in which this happens, creates one same-named variable for each parameter of the function. (9.2 Invoking function, in the official Power Query language specification).
- The function-body can reference variables that are present in the environment when the function is initialized. (9.6 Functions and environments, in the official Power Query language specification)
For our example this means the following:
- The function (Q)=> is invoked in the environment of the inner CorrectTypes.
- This environment creates a variable named Q, corresponding to the parameter Q of the function.
- In this way, we bind the expression Q[Customer] and Q[Date] to the inner table CorrectTypes, as you can see in the following screenshot
Now you may think: Okay, but why all this to bind [Customer] and [Date] to the inner table CorrecTypes, even though they were bound before? That’s a good question. The reason is, that the non prefixed versions of [Customer] and [Date] are now automatically bound the outer table CorrectTypes. This becomes clearer, when you see the alternative writing of the screenshot above (see the official documentation for more details):
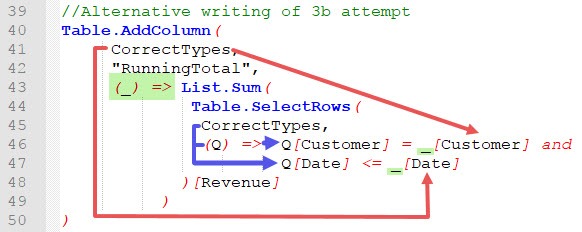
When the inner each existed, both fields were bound to the inner table CorrectTypes. Now that the inner each has been replaced by (Q) =>, both non prefixed fields are automatically bound to the outer each. Because (_) => is invoked in the environment of the outer table CorrectTypes, we bind _[Customer] and _[Date] to the outer table CorrectTypes, which makes our calculation of the running total work 🙂 Done!
We know this was a very long and tough ride through the environment concept in M. Thanks for staying with us. We hope that we were able to convey the importance of this concept. We also hope that we have succeeded in making you understand our present state of understanding of this concept. Just keep in mind: There is always an environment and your understanding of it could be the reason why your current M-Code doesn’t work 😉
Quick recap
What did we see so far?
- More complex custom M code often uses nested function, evaluated in different environments
- Those functions often need to reference to variables from other environments
- This can be obtained by using (Parameter)=> instaed of each. The environment, in which the (Parameter)=> is invoked, creates one same-named variable for each parameter of the function.
- The function-body can then reference variables from the environment, in which the function was defined.
- In this way, you can control which expression is bound to which environment.
Regards from Germany,
Lars & Imke
I write my posts for you, the reader. Please take a minute to help me write my posts as well as possible. Thank you 🙂
[yasr_visitor_multiset setid=2]

Lars ist Berater, Entwickler und Trainer für Microsoft Power BI. Er ist zertifizierter Power BI-Experte und Microsoft Trainer. Für sein Engagement in der internationalen Community wurde Lars seit 2017 jährlich durch Microsoft der MVP-Award verliehen. Lies hier mehr…
Richard meint
Hi Lars,
I just wanted to say thank you so much for this series of articles. I’ve read three Power Query books trying to understand this behaviour and none of them covered it!
The best they do is explain that ‚each‘ is equivalent to ‚(_) =>‘ without touching on the implications when you use ‚each‘ more than once.
It now makes sense to me, FINALLY! 😀
Piotr meint
Thank you very much for such a great and in-depth explanation. Amazing learning experience.
Gentlemen’s, challenge for you, is how to calculate the running total by grouping as in your example however to use the if statement to evaluate if the next sum will result in a quantity greater than the current calculated row and if it does add a reference value to the current row before it calculates next step.
something like this.
Taylor meint
Thank you so much Lars for your write up of this formula and your contributions to the Power Query community. After adding the step with your code, it seems to be calculating correctly on my sample data, but when I implement with a large table (40.000 rows) the process is taking a long time. I have left PowerBI to calculate for about one hour, and only 41 rows have loaded so far. Is there something I can do differently to make it run faster?
Table.AddColumn(Added Custom3, „New Client Billed Amount“, each List.Sum(
Table.SelectRows(
#“Added Custom3″,
(Q) => Q[ProjectNumber] = [ProjectNumber]) [ClientBilledAmount]
))
Lars Schreiber meint
Hey Taylor,
thanks for your positive feedback 🙂 Calculating a running total the way Imke and I did it in this post, is REALLY slow and was just used for didactical reasons. You shouldn’t calculate a running total this way. Imke has spent some time on finding more performant ways to do that and she describes it on her own blog here: https://www.thebiccountant.com/2018/09/30/memory-efficient-clustered-running-total-in-power-bi/.
Have wonderful holidays,
Lars
Michiel Soede meint
Hi Lars and Imke, how is such a solution performing compared to a dax computer running total?
Either way nice solution which is definitely useful.
Thanks Michiel
Lars Schreiber meint
Hi Michiel,
thanks for your message. The running total in M was more a didactical example, than a best practise. There are not many scenarios that come to my mind, where I would create a running total in M, rather than in DAX (Imke is welcome to disagree here 🙂 ). Usually you need the running total to be computed when a filter is selected, and not while refreshing the model. This is why I never tried to compare running totals in M vs. DAX. Does that make sense?
Thanks,
Lars
Michiel Soede meint
Clear and indeed not sure when you would do so if you master dax (but that’s still a bit the area which requires some investment :-)). Thanks and keep up the good work
Giedrius meint
Hello ! Thank you for your great article. I have a question: when I try to realize the more simple scenario (like in your picture „2. Result“ – just summing up the whole column without any grouping) and put it into a function, after I invoke the function from another query I get Error instead of total in the last column. In other words the query works fine when it is stand-alone, but gives me Error when I put it in a function. What could be of a problem here?
Den meint
Thanks for the article and the link to the official documentation (which I have not read before, except about the syntax of the individual functions). It was today that I understood with the similar use of nested functions, which were implemented by Imke in the solution https://social.technet.microsoft.com/Forums/en-US/1275f33f-71df-41ee-914f-c482d2f0678e/sumifs-in-power-query-rolling -12-months
Unfortunately for my task I could not find a solution. If you can, please see the question https://social.technet.microsoft.com/Forums/en-US/062b7459-493c-418f-975f-202e4d958024/sumifs-in-power-query
Frank Tonsen meint
This is a great example for row context in M. I would propose a slight adjustment:
„•We replace the underscore bei Q. Q could have been anything else (e. g. Outer).“
Although this is correct, I think „(e. g. Outer)“ is confusing here. I would change it to „(e. g. Inner)“.
Lars Schreiber meint
Hi Frank,
thanks for that hint. Already changed Outer to Inner. The code was different in the beginning, and after changing it „Outer“ didn’t make any sense. Good finding 😉
Cheers,
Lars